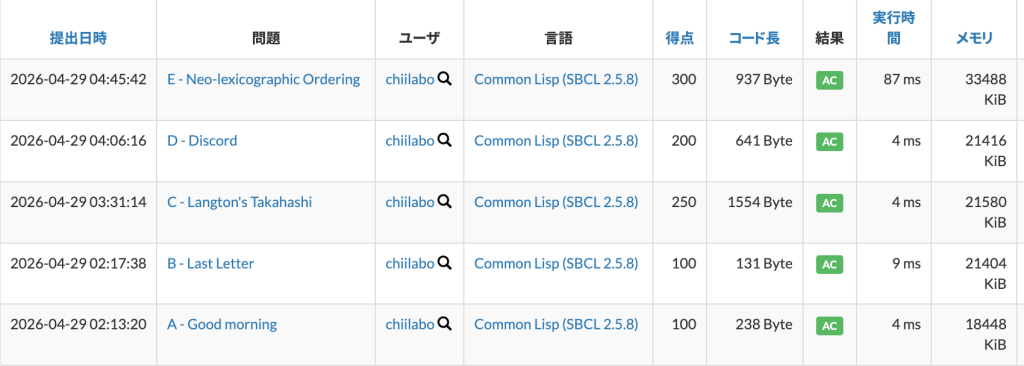
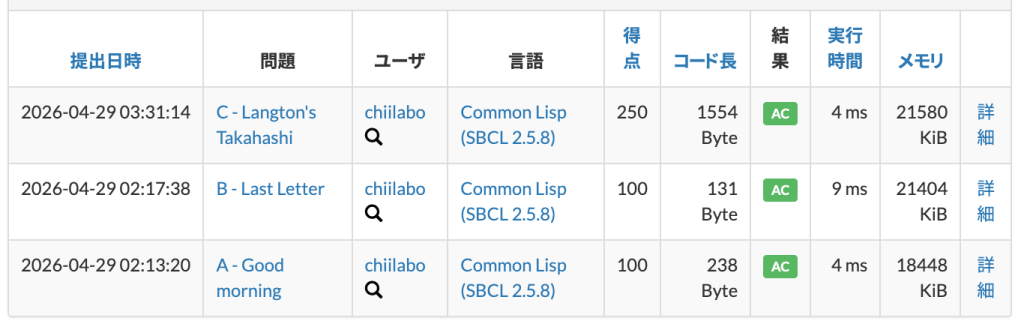
1. A – Good morning
先に A C を比較して、A=Cは、B Dを判定しました。
(defun early-p (A B C D)
(cond ((< A C) t)
((> A C) nil)
(t (<= B D))))
(defun main ()
(let* ((a (read))
(b (read))
(c (read))
(d (read)))
(princ (if (early-p a b c d) "Takahashi" "Aoki"))))
#-swank(main)Code language: Lisp (lisp)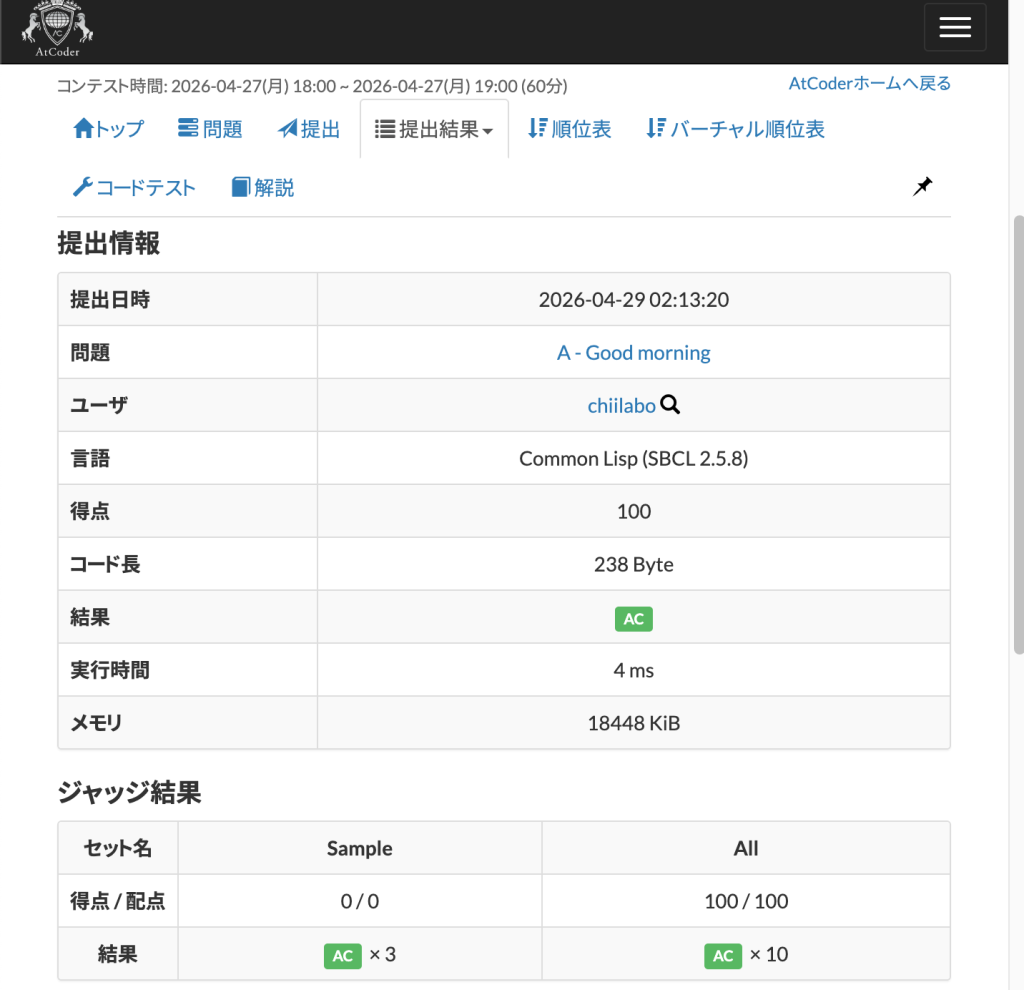
2. B – Last Letter
最後の文字は長さ – 1 の位置にあります。
(defun last-char (s)
(char s (1- (length s))))
(defun main()
(read)
(princ (last-char (read-line))))
#-swank(main)Code language: CSS (css)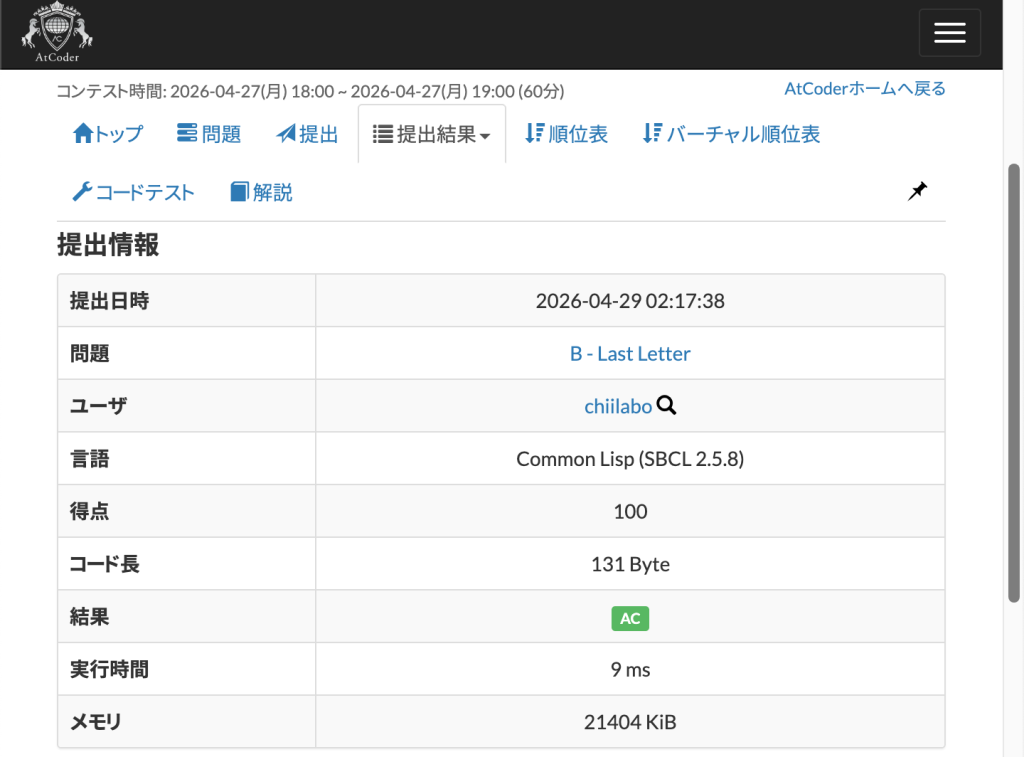
3. C – Langtons’s Takahashi
行・列の座標系は、x-y座標系とは逆なので、時計回り・反時計回りの変換で混乱しました。
あと、はじめは i, j に合わせて 1 〜 H のトーラス位置を求めていましたが、二次元配列の座標に合わせるために、0〜 (H-1) の範囲でアクセスするように直しました。
;; (next-pos '(1 . 2) '(-2 . 1)) ;=> (-1 . 3)
(defun move-pos (pos vec)
(cons (+ (car pos) (car vec)) (+ (cdr pos) (cdr vec))))
(defun torus-pos (pos H W)
(cons (range (car pos) 0 (1- H)) (range (cdr pos) 0 (1- W))))
;; (range 9 1 9) ;=> 9
(defun range (x L R)
(+ L (mod (- x L)
(- R (1- L)))))
(defun next-pos (pos vec H W)
(torus-pos (move-pos pos vec) H W))
;; (rotate-l '(-1 . 0)) ;=> (0 . -1)
(defun rotate-l (vec)
(cons (- (cdr vec)) (car vec)))
;; (rotate-r '(-1 . 0)) ;=> (0 . 1) (row, col)
(defun rotate-r (vec)
(cons (cdr vec) (- (car vec))))
;; (grid->string #2A((#\a #\b) (#\c #\d))) ;=> ("ab" "cd")
(defun grid->string (grid)
(loop for i below (array-dimension grid 0)
collect (loop for j below (array-dimension grid 1)
collect (aref grid i j)
into lst
finally (return (coerce lst 'string)))))
(defun langton-move (H W n)
(loop repeat n
with grid = (make-array
(list H W) :initial-element #\.)
with pos = '(0 . 0)
with vec = '(-1 . 0)
if (eql (aref grid (car pos) (cdr pos)) #\.)
do (setf (aref grid (car pos) (cdr pos)) #\#)
(setf vec (rotate-r vec))
(setf pos (next-pos pos vec H W))
else
do (setf (aref grid (car pos) (cdr pos)) #\.)
(setf vec (rotate-l vec))
(setf pos (next-pos pos vec H W))
end
finally (return grid))
)
(defun main ()
(let* ((lines (grid->string (langton-move (read) (read) (read)))))
(loop for s in lines
do (format t "~a~%" s))))
#-swank(main)Code language: Lisp (lisp)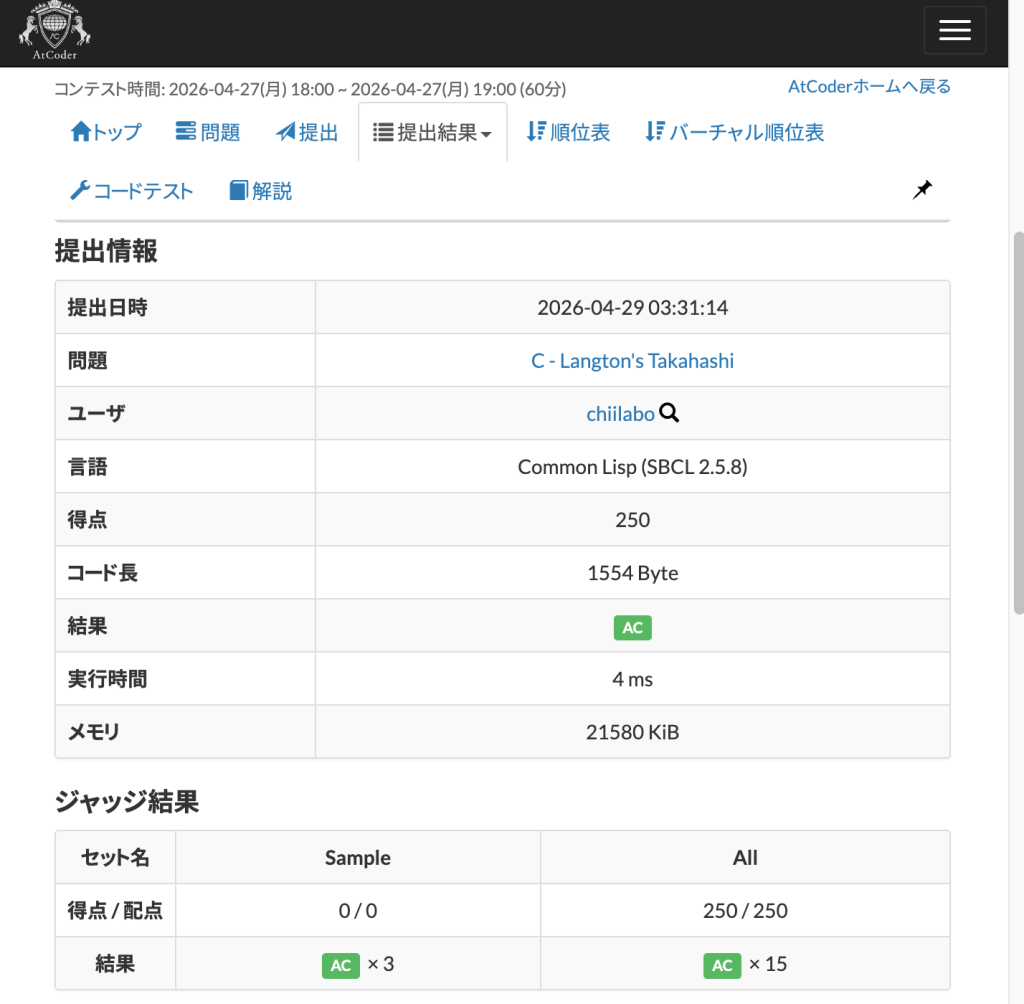

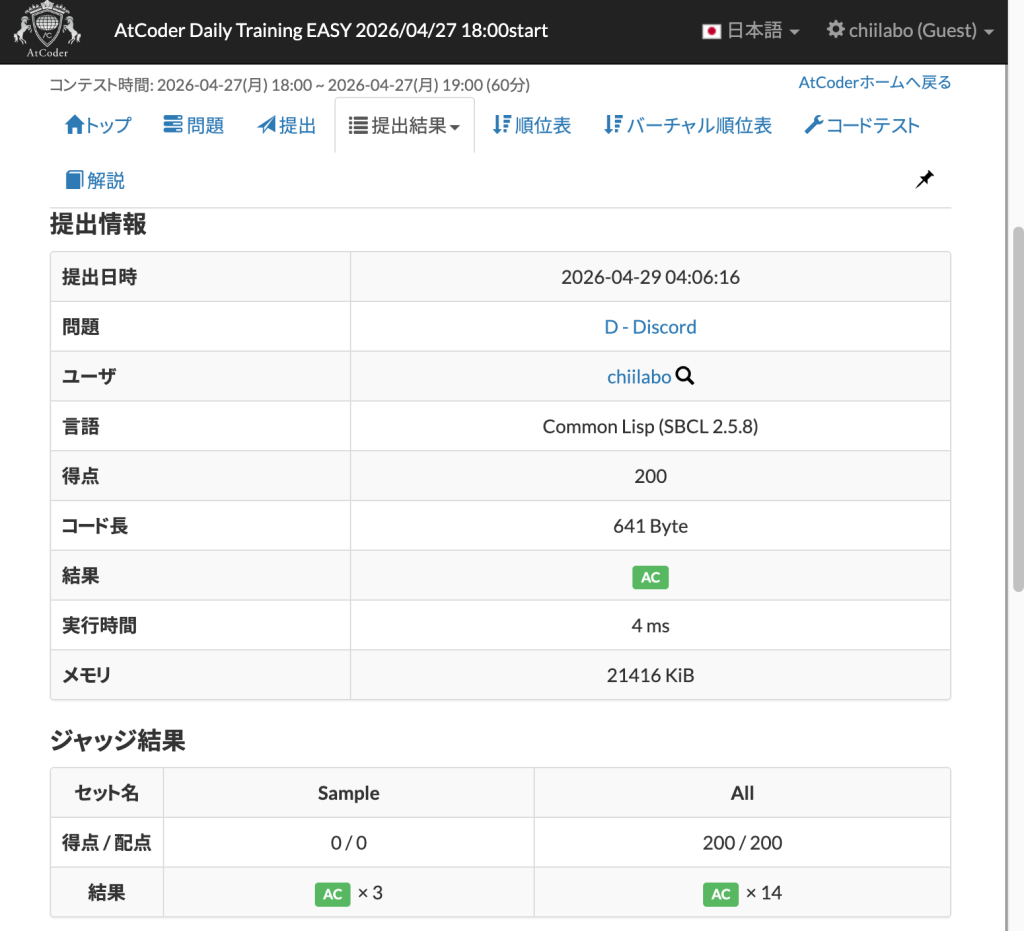
4. D – Discord
まずは、dp[N, N]に不仲ではないペアを記録しました。
分配束縛で隣り合う i, j は、不仲ではないことになります。
重複を避けるため番号のdp[小さい, 大きい]に真を記録しました。
あとは、dpの表の重複を避けた三角形の部分から t をカウントし、全体の組み合わせから引けば完了です。
(defun friendly-pairs (N Amn)
(loop with dp = (make-array (list N N)
:element-type 'boolean
:initial-element nil)
for An in Amn
do (loop for (i j) on An
while j
do (setf (aref dp (1- (min i j)) (1- (max i j))) t))
finally (return (count-dp-friendly dp N))))
(defun count-dp-friendly (dp N)
(loop for i from 0 below N
sum (loop for j from (1+ i) below N
count (aref dp i j))))
(defun main ()
(let* ((N (read))
(M (read))
(Amn (loop repeat M
collect (loop repeat N
collect (read)))))
(princ (- (/ (* N (1- N)) 2)
(friendly-pairs N Amn)))))
#-swank(main)Code language: Lisp (lisp)複雑でしたが、意外とすんなり正解しました。
5. E – Neo-lexicographic Ordering
辞書順に並べ替えるのを自分で実装するのは大変なので、いったん通常のアルファベットに対応させて変換し、並べ替えてから元のアルファベットに戻すことにしました。
(defun encode (s rule-table)
(map 'string #'(lambda (ch)
(gethash ch rule-table))
s))
;; (encode "ccbaaca" (getf (make-rule-tables "cab") :encoder))
;; => "aacbbab"
(defun make-rule-tables (str)
(loop for ch across str
for normal-code from (char-code #\a)
with encoder = (make-hash-table)
with decoder = (make-hash-table)
do (setf (gethash ch encoder) (code-char normal-code))
(setf (gethash (code-char normal-code) decoder) ch)
finally (return (list :encoder encoder :decoder decoder))))
(defun main ()
(let* ((X (read-line))
(N (read))
(Sn (loop repeat N collect (read-line)))
(rules (make-rule-tables X))
(enc (getf rules :encoder))
(dec (getf rules :decoder))
(encoded-Sn (loop for s in Sn
collect (encode s enc)))
(sorted (sort encoded-Sn #'string<=)))
(loop for s in sorted
do (princ (encode s dec))
(princ #\Newline))))
#-swank(main)Code language: Lisp (lisp)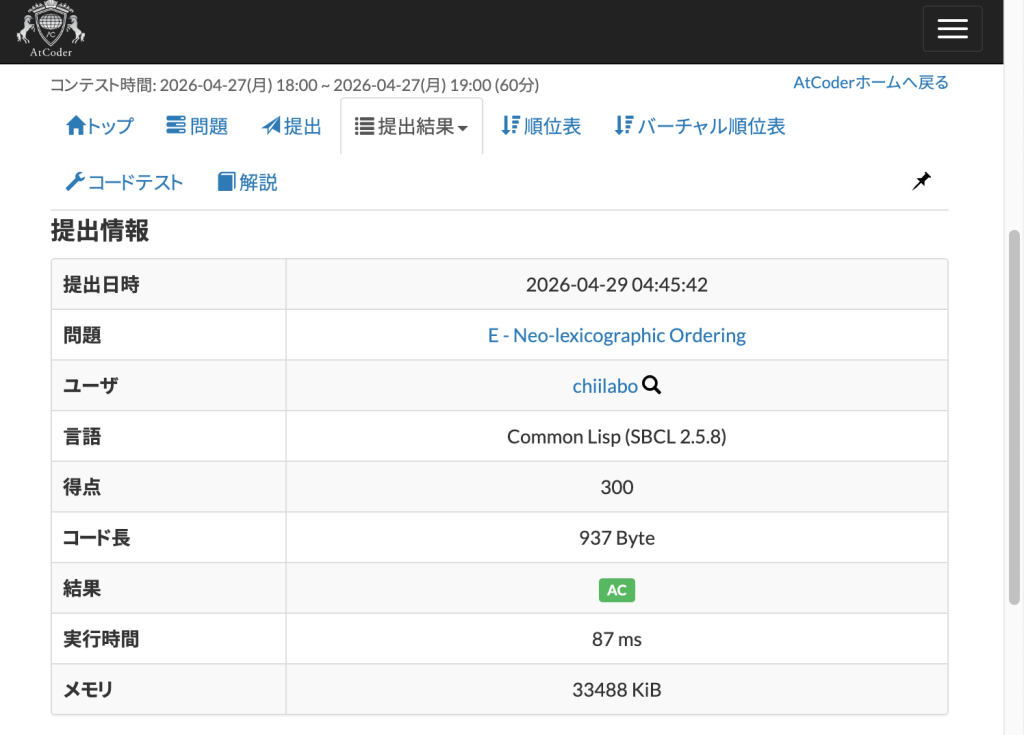
この問題には、もっと効率的な別解があります。