- 部分文字列の長さをキーにした再帰DPを試みたが、末尾の文字情報が消えて破綻した。
- naive版(全列挙)とブルートフォースチェックで反例を特定し、部分問題が独立していないと気づいた。
- 状態を「末尾の文字」に変えたことで、更新式が
f'[x] = sum + 1というシンプルな形に整理された。 - Common Lispでは
loop+make-hash-tableの組み合わせで、添字なしのDPをすっきり書ける。
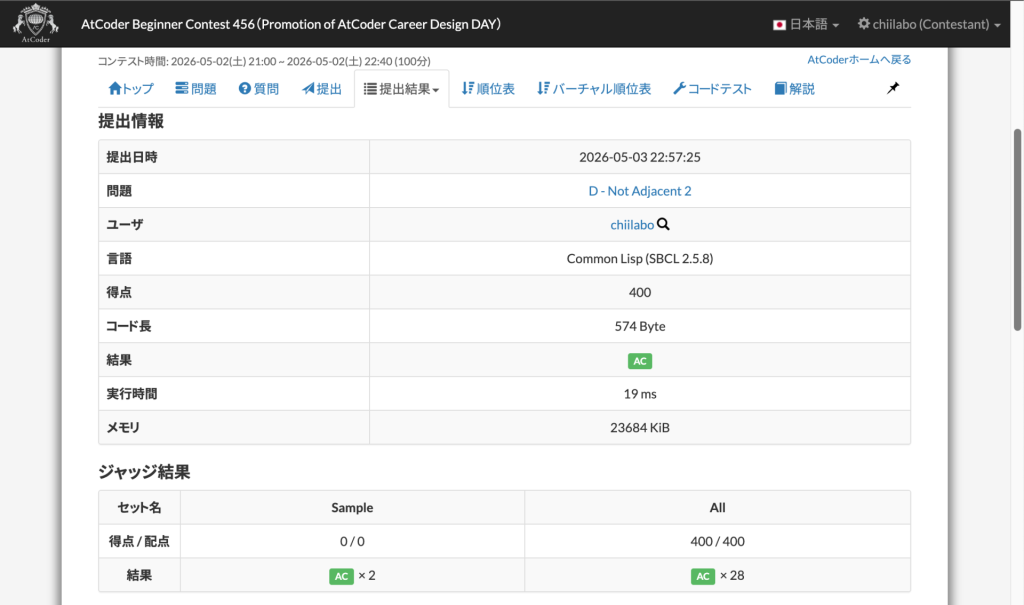
1. 問題 D – Not Adjacent 2
AtCoder ABC456D「Not Adjacent 2」は、a b c からなる文字列Sが与えられ、同じ文字が隣り合わない空でない部分列の個数を 998244353 で割った余りを求める問題です。
「部分列」はSから0文字以上取り除いて残りを元の順序で連結したもので、取り出す位置が異なれば文字列として同じでも別物として数えます。
たとえば abbc の答えは11です。
1.1. まず再帰DPを試みた
再帰で解こうとしました。
部分文字列の長さを状態として、dp[len] にその長さの部分文字列から作れる部分列の個数を持つ設計です。
再帰の考え方はこうでした。
- 基底ケース:長さ0なら0、長さ1なら1
- 再帰ケース:末尾文字と異なる最後の位置(
position-diff-from-end)までの部分問題と、1文字短い部分問題を組み合わせる
(defparameter *prime* 998244353)
(defun last-char (str)
(cond ((= (length str) 0) nil)
(t (char str (1- (length str))))))
(defun position-diff-from-end (str)
(let ((pos (position-if (lambda (ch)
(char/= ch (last-char str)))
str :from-end t)))
(cond ((null pos) 0)
(t (1+ pos)))))
;; (rec (subseq substr 0 n))
;; base case -- "a" => 1 , "" => 0
;; recursive -- rec(n) = with(rec(k) + 1) + without rec(k)
;; where k = ()
;; TODO: something wrong, because "ab"+"a" -/=> "a"+"a"
(defun count-not-adjacent-subseq (str)
(labels ((rec (str dp)
(let* ((len (length str)))
(setf (gethash len dp)
(cond
((gethash len dp))
((= len 0) 0)
((= len 1) 1)
(t (mod
(+ (rec (subseq str 0
(position-diff-from-end str))
dp)
1
(rec (subseq str 0 (1- len)) dp))
*prime*)))))))
(let ((dp (make-hash-table)))
(rec str dp))))Code language: Lisp (lisp)手計算で "abba" を追うと合っているように見えました。
;; (count-not-adjacent-subseq/naive "abbab") ;=> 10
;; for "abbaba"
A(0)= 0
A(1)= A(0)+1+A(0)-A(0) a 1
A(2)= A(1)+1+A(1)-A(0) b 3
A(3)= A(2)+1+A(1)-A(0) b 5
A(4)= A(3)+1+A(3)-A(1) a 10Code language: PHP (php)ところが、長いテストケース *S* で照合したところ、答えが合いませんでした。
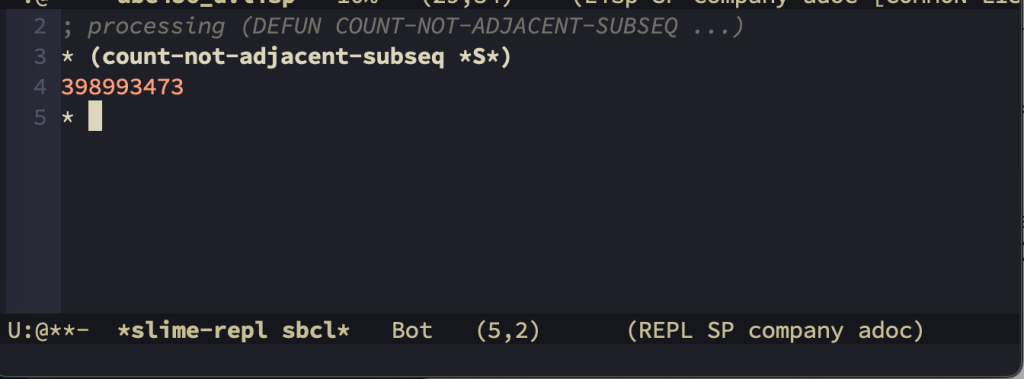
「378217423」を期待したのに、「398993473」と出てくるのです。
2. ブルートフォースチェックで反例を特定した
そこで、ブルートフォースチェックで反例を探しました。
naive版は全部分列を列挙してフィルタリングする方法です。
(defun make-substrings (str)
(labels ((push-char (ch str)
(concatenate 'string (string ch) str))
(rec (str)
(cond
((= (length str) 0) '(""))
(t (let ((ch (char str 0))
(rest (rec (subseq str 1))))
(append
(loop for s in rest
collect (push-char ch s))
rest)))
)))
(remove "" (rec str) :test #'equal)))
(defun not-adjacent-p (str)
(cond ((<= (length str) 1)))
(loop for i below (1- (length str))
for a = (char str i)
for b = (char str (1+ i))
always (char/= a b)))
(defun count-not-adjacent-subseq/naive (str)
(mod (count-if #'not-adjacent-p (make-substrings str))
*prime*))Code language: Lisp (lisp)make-strings-pattern で長さNの全パターンを生成して、2つの実装を突き合わせます。
不一致が出たら即座に反例が表示されます。
(defun test (N)
(loop for s in (make-strings-pattern "abc" N)
when (/= (count-not-adjacent-subseq s)
(count-not-adjacent-subseq/naive s))
do (print s)))Code language: Lisp (lisp)小さいNで全パターンを網羅できるうちに間違いを潰せる、定番の検証手法です。
2.1. 反例を手で追って気づいた
反例を手で追いながら、A(n) を A(n-1) 以前の項で表そうとしました。
すると、引く項が文字列の内容によって変わります。
;; (count-not-adjacent-subseq/naive "abbab") ;=> 10
;; for "abbaba"
A(1)= A(0)+1+A(0)-A(0) a 1
A(2)= A(1)+1+A(1)-A(0) b 3
A(3)= A(2)+1+A(1)-A(0) b 5
A(4)= A(3)+1+A(3)-A(1) a 10
A(5)= A(4)+1+A(4)-A(2) b 17Code language: PHP (php)A(3) と A(5) はどちらも文字 b を追加していますが、引く項が A(0) と A(2) で異なります。
長さだけをキーにしても漸化式が一意に定まらず、文字列の中身を別途参照しなければ式が書けません。
これは「長さによるDP」として成立していないと判断しました。
3. 解説を見て更新式に含める状態を考え直した
公式解説を見ると、注目すべき状態は「末尾の文字」でした。
もらう DP の遷移を考えます。
例として を求めることを考えます。解説 – AtCoder Beginner Contest 456(Promotion of AtCoder Career Design DAY)
- のとき、 を使うことはできません。
よって です。- のとき、 を使わないケースが 通り、 を使う長さ 2 以上の部分列では の前が
aであってはならないので 通り、 を使う長さ 1 の部分列が 通りとなります。
そこで、f[a], f[b], f[c] の3つを持つことにしました。f[x] の意味を「末尾が x で終わる部分列の個数(位置違いも全て別カウント)」とします。
また、f[x] は i 文字目を処理した後の値とし、f'[x] は i+1 文字目を処理した後の値とします。
Sを左から1文字ずつ処理して、i文字目が x のとき f[x] だけ更新します。
更新式を導出します。
「x を末尾に追加できる部分列」は、今ある全部分列から末尾が x のものを除いたものです。
そこに x 単体の1個を足すので、新たに追加される個数は:
(f[a] + f[b] + f[c]) - f[x] + 1Code language: CSS (css)これを f[x] に足し込む必要があります(上書きではなく)。
f'[x] = f[x] + (sum - f[x] + 1)
= sum + 1x を末尾に追加するとき引くはずの f[x] が、足し込む操作と打ち消し合って消えます。
結果として非常にシンプルな形になりました。
f'[x] = sum + 1 (sum = f[a] + f[b] + f[c])
f'[y] = f[y] (y ≠ x)
Code language: PHP (php)abbc で追ってみます。
| 見た文字 | f[a] | f[b] | f[c] | sum |
|---|---|---|---|---|
| 初期 | 0 | 0 | 0 | 0 |
| a | 1 | 0 | 0 | 1 |
| b | 1 | 2 | 0 | 3 |
| b | 1 | 4 | 0 | 5 |
| c | 1 | 4 | 6 | 11 |
合計11で、期待値と一致します。
3.1. Common Lisp での実装
make-hash-table で #\a #\b #\c をキーにします。loop の for sum = で毎ステップ更新前の合計を計算してから f[x] を上書きするのがポイントです。
(defun count-not-adjacent-subseq (str)
(let ((ht (make-hash-table)))
(loop for ch across str
for sum = (+ (gethash #\a ht 0)
(gethash #\b ht 0)
(gethash #\c ht 0))
do (setf (gethash ch ht)
(mod (1+ sum) *prime*)))
(mod (+ (gethash #\a ht 0)
(gethash #\b ht 0)
(gethash #\c ht 0))
*prime*)))
Code language: Lisp (lisp)gethash の第3引数にデフォルト値0を渡すので、初期化が不要です。test で全パターンを検証してパスしました。
4. 何が問題だったか
| 試みた方針 | 問題点 |
|---|---|
| 長さをキーにした再帰DP | 末尾の文字情報が消え、部分問題が独立しない |
| 末尾の文字を状態にしたループDP | 状態が3つだけ、O(N)で解ける |
再帰DPを設計するとき「何を状態として持つか」が全てです。
今回は長さではなく末尾の文字が必要でした。
ブルートフォースチェックがあったおかげで、方針の誤りを早い段階で確認できました。
4.1. 完成したコード
(defparameter *prime* 998244353)
(defun count-not-adjacent-subseq (str)
(let ((ht (make-hash-table)))
(loop for ch across str
for sum = (+ (gethash #\a ht 0)
(gethash #\b ht 0)
(gethash #\c ht 0))
do (setf (gethash ch ht)
(mod (1+ sum) *prime*)))
(mod (+ (gethash #\a ht 0)
(gethash #\b ht 0)
(gethash #\c ht 0))
*prime*)))
(defun main ()
(let* ((s (read-line)))
(princ (count-not-adjacent-subseq s))))
#-swank(main)Code language: PHP (php)