- 優先度付きキューは最小値だけをすぐ取り出せるデータ構造で、全体をソートする必要はありません。
- 実装は「未整理リスト、ソート済みリスト、ヒープ順序木、完全二分木ヒープ、配列ヒープ」と段階的に改善でき、各段階で消したコストが明確になります。
- ヒープ条件は「親は子より優先度が高い」という局所的な規則で、木の形は問いません。完全二分木への固定と配列への写しは、それぞれ独立した改善です。
- 二分ヒープはソート済みリストより弱い秩序しか保ちませんが、それで十分なため push・pop ともに O(log n) になります1。
1. 優先度付きキューとは
「優先度付きキュー(Priority Queue)」は、「優先度が高い順に取り出す」データ構造です。
要は、データを出し入れしながら、一番小さな数や一番大きな数を取り出すためのキューで、常に全体の最小値を更新するときなどには有効です。
つまり、「優先度」とは、最小・昇順や最大・降順を一般化した言い方で、あとの説明では主に「最小値」を求める「最小ヒープ」を考えます(「ヒープ」については後述)。
要素を追加するだけならかんたんですが、要素を取り除いたときには、次の最小値を探す必要があります。
最小値を探しやすく要素の出し入れする設計が、優先度付きキューの特徴です。
優先度付きキューは、通常のキューのように要素を出し入れします。
push:要素を追加するpop:最小値(または最大値)を取り出すpeek:取り出さずに最小値を確認する
最小値や最大値を順に求める場面としては、たとえば Dijkstra法では「距離が最小の頂点から処理する」ために、ヒープソートでは「最大値を繰り返し取り出す」ために使われます2。
1.1. 優先度付きキューの実装と計算量
Common Lispには標準の優先度付きキューがないので、自分で実装します。
実装を改善していく視点は「何のコストを消すか」です。
| 実装 | 行数 | push | pop |
|---|---|---|---|
| 未整理リスト | 22 | O(1) | O(n) |
| ソート済みリスト | 24 | O(n) | O(1) |
| ヒープ順序木(pairing heap) | 55 | O(1) | O(log n) 均し |
| 完全二分木ヒープ(ポインタ木) | 95 | O(log n) | O(log n) |
| 完全二分木ヒープ(配列実装) | 68 | O(log n) | O(log n) |
通常、「二分ヒープ(binary heap)」という場合には、配列実装の完全二分木ヒープのことをいうことが多いです。
2. リストから取り出すときに最小値を探す
もっとも素朴な考え方は、リストに要素を入れて、取り出すときに最小値を探す、というものです。
naive-pqではデータ構造として、リスト data と比較関数 order(#'< や#'> を持つ)をセットで持ちます。
(defstruct naive-pq
(data nil)
(order #'<))
(defun pq-empty-p/naive (pq)
(null (naive-pq-data pq)))Code language: Lisp (lisp)push は先頭への追加なので O(1) です。
(defun pq-push/naive (pq x)
(push x (naive-pq-data pq))
pq)
Code language: Lisp (lisp)pop は、リスト全体から最小値を探し、取り出します。
(defun pq-pop/naive (pq)
(assert (not (pq-empty-p/naive pq)))
(let* ((data (naive-pq-data pq))
(order (naive-pq-order pq))
(best (reduce (lambda (a b) (if (funcall order a b) a b)) data)))
(setf (naive-pq-data pq)
(remove best data :count 1 :test #'eq))
best))Code language: Lisp (lisp)動作を確認します。
(let ((pq (make-naive-pq)))
(pq-push/naive pq 5)
(pq-push/naive pq 2)
(pq-push/naive pq 8)
(pq-pop/naive pq))
;=> 2Code language: Lisp (lisp)push で積んだ順序は (8 2 5) ですが、pop は最小値の 2 を返します3。
ただし、このままでは、pop がリスト全体を毎回走査するため O(n) になることです。
100要素なら100回、10000要素なら10000回の比較が pop のたびに発生します。
2.1. 入れるときに並べておく(ソート済みリスト)
pop が遅いのは「どこに最小値があるか知らない」からで、「最初から並べておけばよい」というのが「ソート済みリスト」の発想です。
データ構造は、未整理リストと同じです。
(defstruct sorted-pq
(data nil)
(order #'<))
(defun pq-empty-p/sorted (pq)
(null (sorted-pq-data pq)))Code language: Lisp (lisp)push で挿入するときに、order順になるような場所まで辿って、そこでセルを作ります。
(defun pq-push/sorted (pq x)
(let ((order (sorted-pq-order pq)))
(labels ((insert (lst)
(cond
((null lst) (list x))
((funcall order x (car lst)) (cons x lst))
(t (cons (car lst) (insert (cdr lst)))))))
(setf (sorted-pq-data pq)
(insert (sorted-pq-data pq)))))
pq)Code language: Lisp (lisp)pop は、先頭を取るだけで O(1) になりました。
(defun pq-pop/sorted (pq)
(assert (not (pq-empty-p/sorted pq)))
(pop (sorted-pq-data pq)))Code language: Lisp (lisp)動作を確認します。
(let ((pq (make-sorted-pq)))
(pq-push/sorted pq 5)
(pq-push/sorted pq 2)
(pq-push/sorted pq 8)
(list (pq-pop/sorted pq)
(pq-pop/sorted pq)
(pq-pop/sorted pq)))
;=> (2 5 8)Code language: Lisp (lisp)2.2. 未整理リストとソート済みリスト
コストの位置が入れ替わりました。
未整理リスト:
push O(1) ── 積むだけ
pop O(n) ── 全体から探す
ソート済みリスト:
push O(n) ── 正しい位置まで探して挿入
pop O(1) ── 先頭を取るだけソート済みリストでは、pop は速くなりましたが push が遅く、交互に大量に呼ぶときにはやはり困ってしまいます4。
3. ヒープ順序木
ソート済みリストの問題は、「全体をきれいに並べる必要があるのか」ということです。
というのも、優先度付きキューに必要なのは「最小値だけすぐ取れること」であって、2番目以降が整列している必要はないからです。
この過剰さを削るのが次の段階である「ヒープ条件」です。
3.1. ヒープ条件という考え方
優先度付きキューに必要な条件は、「先頭に最小値がある」だけです。
これだけが保証されていれば、pop で最小値をすぐ取り出せます。
リストを枝分かれした木構造にすれば、2番目以降が完全に整列している必要はありません。
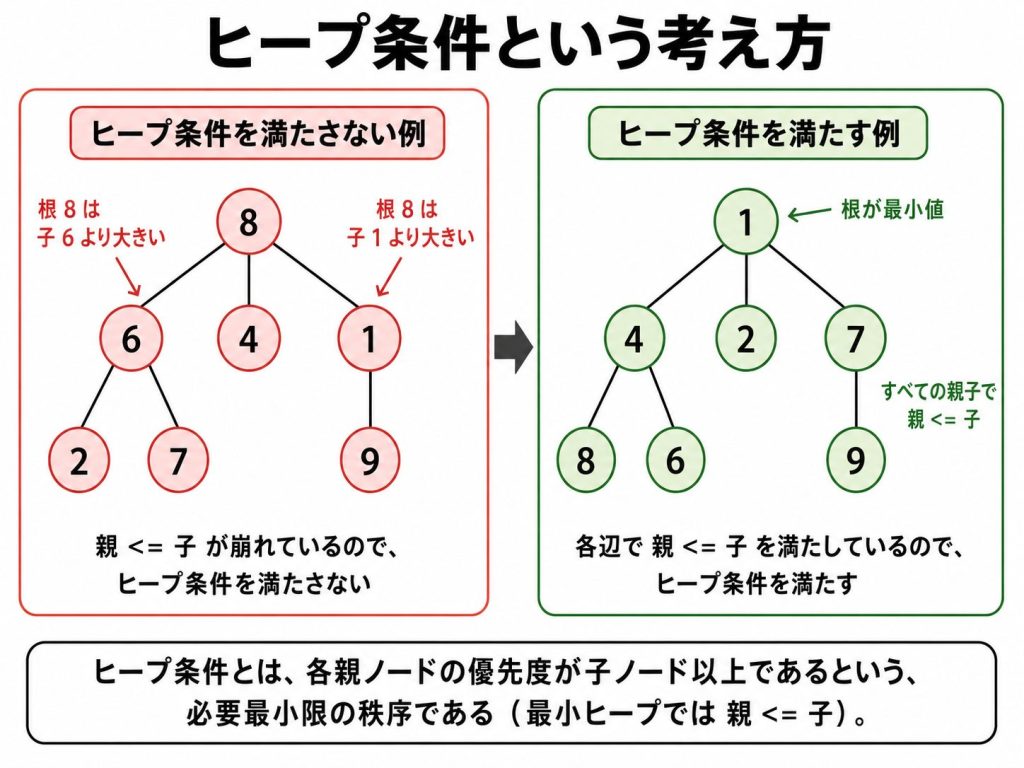
この必要最小限の秩序を「ヒープ条件」といい、それを満たすデータ構造を「ヒープ」といいます。
「ヒープ(heap)」とは、「山積み」「雑多な集まり」を意味し、ここでは「親要素は子要素より常に優先度が高い(最小ヒープなら親 <= 子)」という規則に従うデータ構造です5。
「ヒープ条件」は、メモリ割り当てでの「ヒープ領域」とは、もとの単語は同じですが、直接関係ありません。
必ずしも、ヒープ領域を使うデータ構造というわけではありません。
ソート済みリストは「1番目、2番目、3番目……すべての順序」を保ちます。
一方、ヒープは「根だけが最小値」という条件しか保たないので、整列範囲は各枝だけを見ればよいことになり、コストが下がります。
3.2. ヒープ順序木(pairing heap)の実装
ヒープ条件を持つ木の実装の一つに、「pairing heap」があります。
「pairing heap」は、ヒープ順序木を meld で操作する優先度付きキューです。
外側の構造はこれまでと同じく data + order です。
(defstruct pairing-pq
(data nil)
(order #'<))
(defun pq-empty-p/pairing (pq)
(null (pairing-pq-data pq)))Code language: Lisp (lisp)ただし、data の中身は線形リストではなく、コンスセルで表した木構造になります。
1つのノードを (キー . 子リスト) で表し、car がキー、cdr が子ヒープのリストです。
たとえば、ヒープ条件を満たす木は、このようにリストで書けます。
(1 (4 ((8) (6))) (2) (7 (9)))3.3. pushとmeld
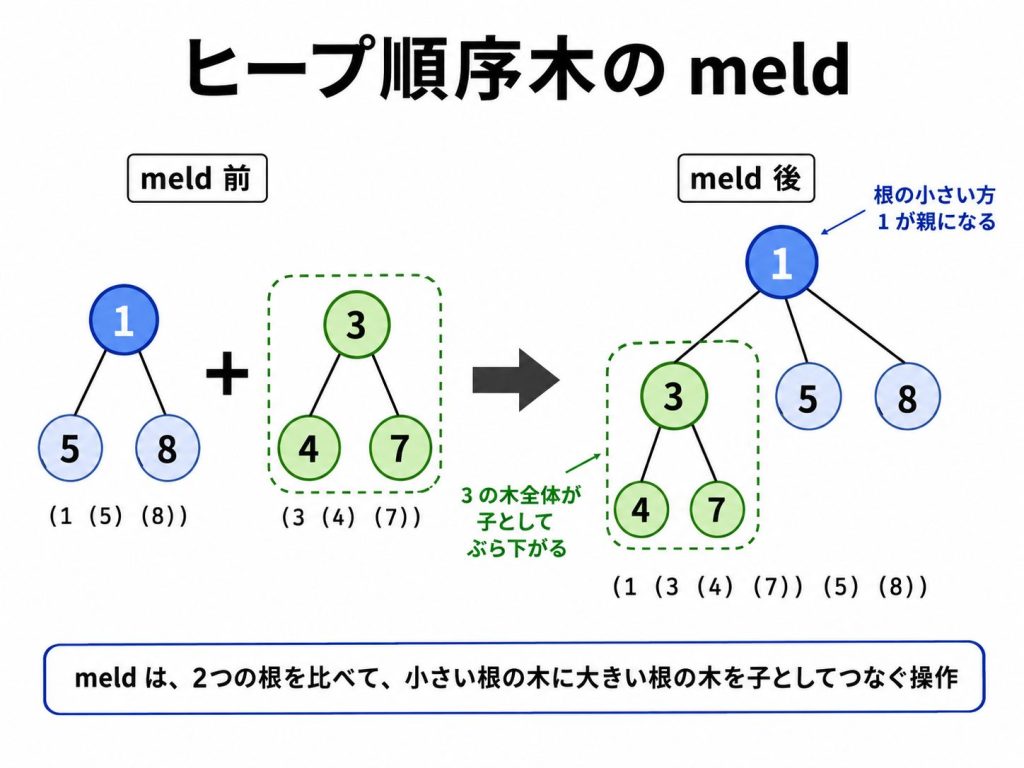
2つのヒープ順序木を合わせる操作を meld と呼びます。
(defun %make-heap-node (key &optional children)
(cons key children))
(defun %meld (a b order)
(cond
((null a) b)
((null b) a)
((funcall order (car b) (car a))
(%meld b a order))
(t
(%make-heap-node (car a)
(cons b (cdr a))))))Code language: Lisp (lisp)Common Lispでは、内部動作となる補助関数は、%で始まる関数名にする慣習があるので、そのようにしています。
ヒープ条件を満たすために、meldでは根の小さい方を親にして、大きい根の木を子としてぶら下げます。
要素を push するには、1要素のヒープ順序木を作ってから meld します。
(defun pq-push/pairing (pq x)
(setf (pairing-pq-data pq)
(%meld (%make-heap-node x)
(pairing-pq-data pq)
(pairing-pq-order pq)))
pq)Code language: Lisp (lisp)3.4. popとpairing meld
pop の仕方には、特徴があります。
根にある最小値を取り出してしまうと、木構造はバラバラになってしまいます。
そこで、根の子どもたちを1つの木に meld していく必要があります。
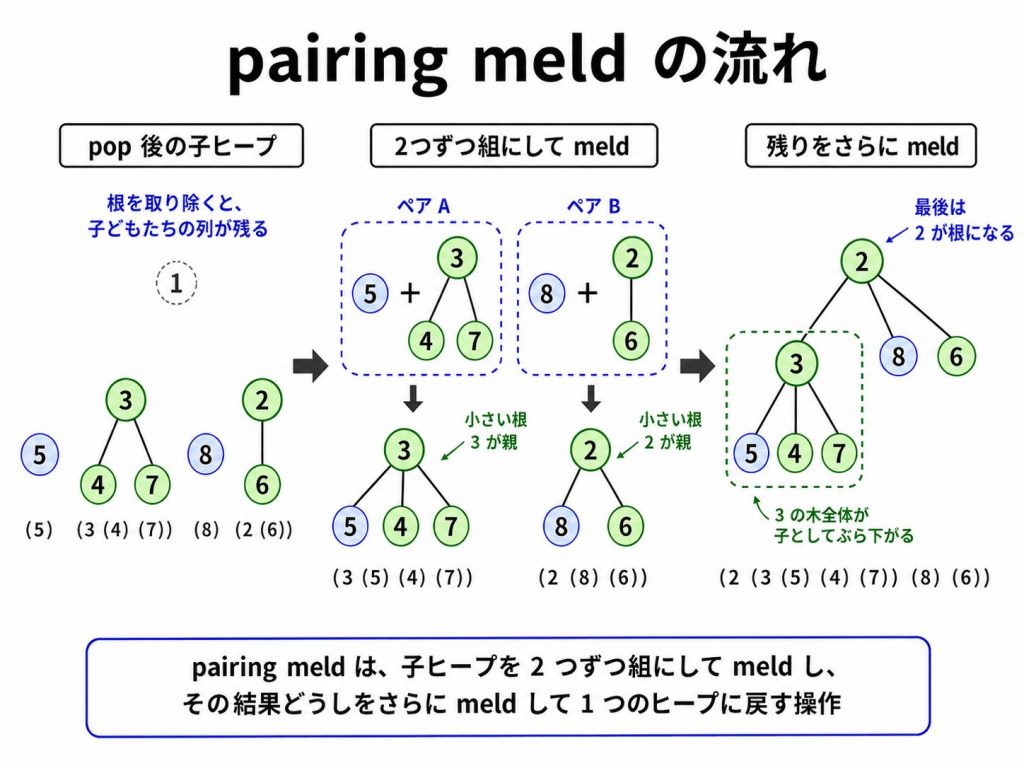
「pairing heap」では、「2つずつ組にして meld 」を繰り返します。
(defun %pairwise-meld (heaps order)
(cond
((null heaps) nil)
((null (cdr heaps)) (car heaps))
(t
(%meld (%meld (first heaps)
(second heaps)
order)
(%pairwise-meld (cddr heaps) order)
order))))Code language: Lisp (lisp)あとは、popで取ります。
(defun pq-pop/pairing (pq)
(let ((h (pairing-pq-data pq)))
(assert h)
(let ((x (car h)))
(setf (pairing-pq-data pq)
(%pairwise-meld (cdr h)
(pairing-pq-order pq)))
x)))
(defun pq-peek/pairing (pq)
(let ((h (pairing-pq-data pq)))
(assert h)
(car h)))Code language: Lisp (lisp)動作を確認します。
(let ((pq (make-pairing-pq)))
(dolist (x '(5 3 8 1 4 2))
(pq-push/pairing pq x))
(loop until (pq-empty-p/pairing pq)
collect (pq-pop/pairing pq)))
;=> (1 2 3 4 5 8)Code language: Lisp (lisp)3.5. この段階で何が変わったか
ヒープ条件の本質は木の形ではなく、親子の辺の向きということです。
ソート済みリスト:
push O(n) ── 全体の中の正しい位置まで探して挿入
pop O(1) ── 先頭を取るだけ
ヒープ順序木(pairing heap):
push O(1) ── 1ノード木を作って meld するだけ
pop O(log n) 均し ── 子を pairwise-meld で再構成push が O(1) になりました。
pop は均し O(log N) で、最悪は O(N) です。
ただし、各ノードが子リストへのポインタを持つため、メモリ割り当てが要素ごとに発生します。
4. 完全二分木で木の形を固定する
ヒープ条件を完全二分木に適用すると、次の追加位置と最後のノードが一意に定まります。
「完全二分木」とは、最下段を除くすべての段が埋まっていて、最下段は左から順に詰まっている木です。
ヒープ条件を満たす完全二分木の例(最小ヒープ):
1 ← 根が最小値
/ \
4 2
/ \ / \
8 6 5 3
2番目以降は整列していないが、
どの親もその子より小さいので、
ヒープ条件は満たしている。木の形を「完全二分木」に固定すると、sift-up と sift-down だけでヒープ条件を回復できます。
4.1. ポインタ木で実装する
まず、ポインタで親子をつなぐ木構造でヒープを実装してみます。
ノードは値・親・左右の子を持ちます。
(defstruct heap-node
value
parent
left
right)
(defstruct pointer-heap
(root nil)
(size 0 :type fixnum)
(order #'<))Code language: Lisp (lisp)size を持つのは、完全二分木の「次に追加する場所」と「最後のノード」を特定するためです。
push と pop の説明で詳しく見ます。
4.2. push:末尾に追加してsift-upする
要素を追加するときは、完全二分木の形を保ちながら末尾に置き、その後ヒープ条件を回復します。
「末尾に追加して、親と比べながら上へ交換していく」操作を sift-up と呼びます。
sift は「ふるいにかけて位置を調整する」という意味です。
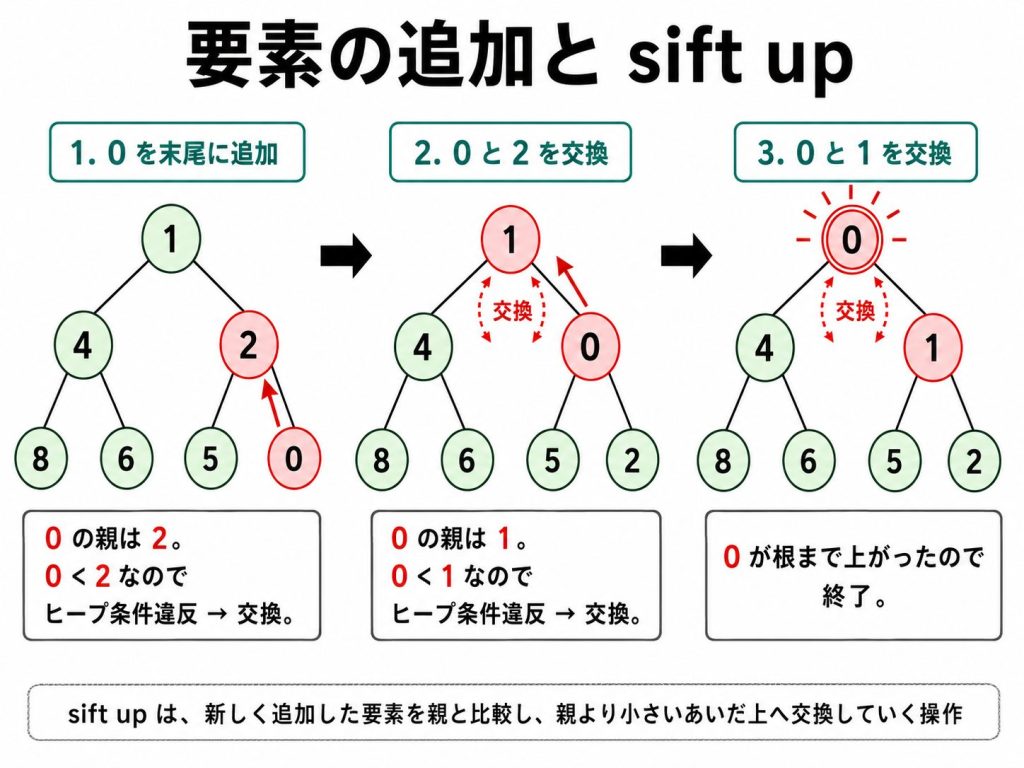
移動するのは木の高さ分だけで、完全二分木の高さは O(log n) です。
実装では、まず「次に追加するノード」の場所を求めるヘルパー %find-node-at を用意します。
(defun %find-node-at (root n)
(if (= n 1)
root
(let* ((bits (integer-length n))
(path (loop for i from (- bits 2) downto 0
collect (logbitp i n))))
(reduce (lambda (node go-right)
(if go-right
(heap-node-right node)
(heap-node-left node)))
path
:initial-value root))))
Code language: Lisp (lisp)完全二分木では、ノードに上から左から番号を振ると、size+1番目が次の追加位置です。
この番号を二進数で表したとき、先頭の 1 を除いたビット列が根からの経路になります6。
size=6(7番目を追加する場合):
7 = 111₂ → 先頭の1を除くと 11
1 は右、1 は右
根 → 右 → 右
size=4(5番目を追加する場合):
5 = 101₂ → 先頭の1を除くと 01
0 は左、1 は右
根 → 左 → 右sift-up は、親と値を比べて必要なら交換し、根まで繰り返します。
ポインタ版では値だけを交換して、ノード自体は動かしません7。
(defun %sift-up/ptr (node order)
(loop while (heap-node-parent node)
for parent = (heap-node-parent node)
while (funcall order
(heap-node-value node)
(heap-node-value parent))
do (rotatef (heap-node-value node)
(heap-node-value parent))
(setf node parent)))Code language: Lisp (lisp)push はこうなります。
(defun heap-push/ptr (h x)
(let ((new-node (make-heap-node :value x))
(size (pointer-heap-size h))
(order (pointer-heap-order h)))
(incf (pointer-heap-size h))
(if (null (pointer-heap-root h))
(setf (pointer-heap-root h) new-node)
(let* ((parent-index (floor (1+ size) 2))
(parent (%find-node-at (pointer-heap-root h) parent-index))
(go-right (evenp (1+ size))))
(setf (heap-node-parent new-node) parent)
(if go-right
(setf (heap-node-right parent) new-node)
(setf (heap-node-left parent) new-node))
(%sift-up/ptr new-node order))))
h)Code language: Lisp (lisp)4.3. pop:根を取り出してsift-downする
pop では根の値を取り出したら、まず最後のノードの値を根に移し、それからヒープ条件を回復するように調整します。
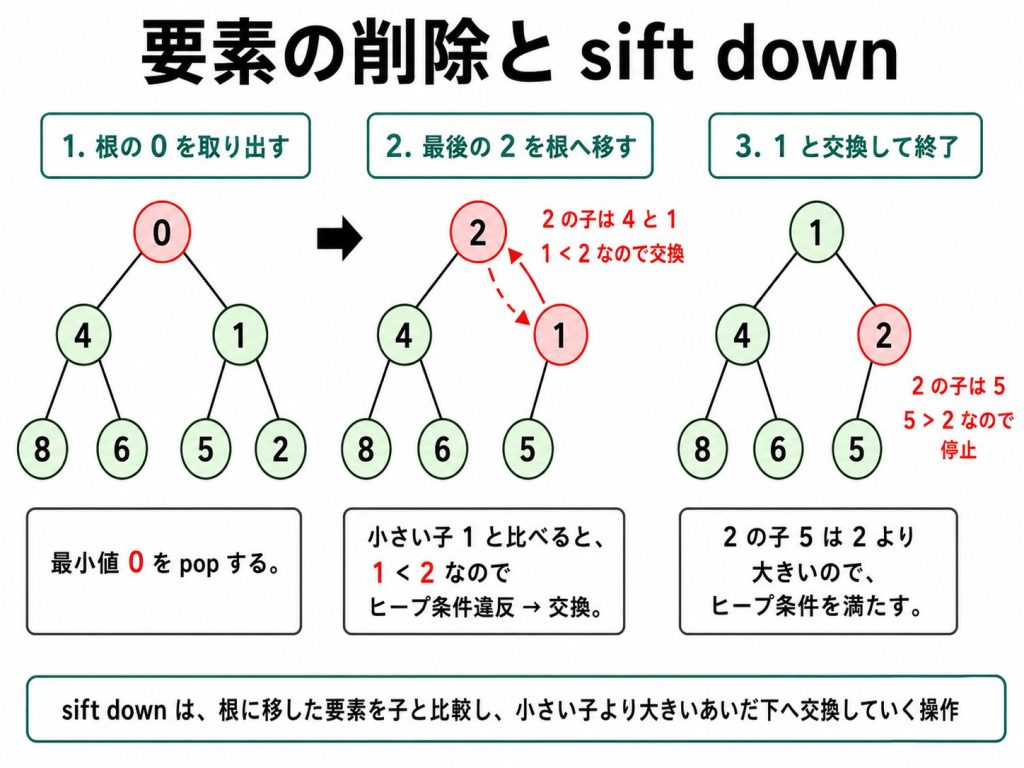
「根に置いた値を、小さい方の子と比べながら下へ交換していく」操作を sift-down と呼びます8。
sift-down の実装です。
(defun %sift-down/ptr (node order)
(loop
(let* ((left (heap-node-left node))
(right (heap-node-right node))
(best node))
(when (and left
(funcall order
(heap-node-value left)
(heap-node-value best)))
(setf best left))
(when (and right
(funcall order
(heap-node-value right)
(heap-node-value best)))
(setf best right))
(if (eq best node)
(return)
(progn
(rotatef (heap-node-value node)
(heap-node-value best))
(setf node best))))))Code language: Lisp (lisp)pop の全体はこうなります。
(defun heap-pop/ptr (h)
(assert (pointer-heap-root h))
(let* ((root (pointer-heap-root h))
(result (heap-node-value root))
(size (pointer-heap-size h))
(order (pointer-heap-order h)))
(if (= size 1)
(setf (pointer-heap-root h) nil)
(let ((last (%find-node-at root size)))
(setf (heap-node-value root) (heap-node-value last))
(let ((parent (heap-node-parent last)))
(if (eq (heap-node-right parent) last)
(setf (heap-node-right parent) nil)
(setf (heap-node-left parent) nil)))
(setf (heap-node-parent last) nil)
(%sift-down/ptr root order)))
(decf (pointer-heap-size h))
result))Code language: Lisp (lisp)動作を確認します。
(let ((h (make-pointer-heap)))
(heap-push/ptr h 5)
(heap-push/ptr h 2)
(heap-push/ptr h 8)
(heap-push/ptr h 1)
(heap-push/ptr h 4)
(list (heap-pop/ptr h)
(heap-pop/ptr h)
(heap-pop/ptr h)))
;=> (1 2 4)Code language: Lisp (lisp)挿入順に関係なく、小さい順に取り出せています。
4.4. この段階で何が変わったか
ポインタ木ヒープ:
push O(log n) ── 末尾に追加して、高さ分だけ上へ
pop O(log n) ── 根を取り出して、高さ分だけ下へ「全体を整列させる」から「ヒープ条件だけを回復する」に変わったことで、push・pop ともに O(log n) になりました。
ただし、この実装にはまだ問題があります。
push のたびに find-node-at が O(log n) の走査をしています。
各ノードが parent・left・right の3つのポインタを持つため、メモリの使い方も重くなります。
次の段階でこれを解消します9。
5. 完全二分木を配列の添字規約で表す
ポインタ木版のアルゴリズムは正しく動きます。
ただし、親子関係をポインタで管理しているため、ノードごとにメモリを割り当てる必要があります。
完全二分木は、添字のルールで配列に対応させることができます。
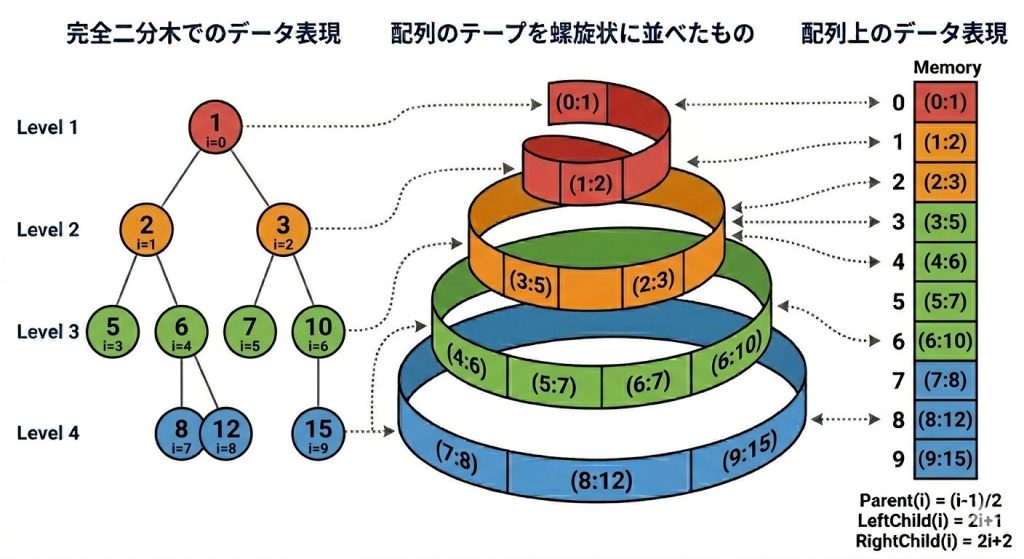
上から順に、左から右へノードに番号を振ると、番号付けで、親子関係が添字の計算式だけで求まります10。
index i の親: floor((i - 1) / 2)
index i の左の子: 2i + 1
index i の右の子: 2i + 2この添字規約を使うと、find-node-at の走査も parent・left・right のポインタも不要になり、コードが簡潔になります。
二分(binary)は、コンピュータのメモリ配置を相性がよいためです。
「二分ヒープ(binary heap)」は、ヒープ条件を満たす完全二分木のことです。
実装としてはポインタ木でも表せますが、完全二分木では親子関係を配列の添字で表せるため、通常は配列で実装されます。
そのため、実用上「二分ヒープ」というと、配列実装の優先度付きキューを指すことが多いです。
5.1. 基本構造
配列版の二分ヒープでは、data を可変長配列で持ちます。
(defstruct heap
(data (make-array 16 :adjustable t :fill-pointer 0))
(order #'<))
(defun heap-size (h)
(fill-pointer (heap-data h)))
(defun heap-empty-p (h)
(zerop (heap-size h)))Code language: Lisp (lisp)親子関係のヘルパーです。
ポインタ版の heap-node-parent・heap-node-left・heap-node-right に対応します。
;;; 補助: 添字計算
(defun %heap-parent (i) (floor (1- i) 2))
(defun %heap-left (i) (1+ (* 2 i)))
(defun %heap-right (i) (+ 2 (* 2 i)))
;;; 補助: 要素アクセスと交換
(defun %heap-ref (h i)
(aref (heap-data h) i))
(defun %heap-swap (h i j)
(rotatef (aref (heap-data h) i)
(aref (heap-data h) j)))
(defun %heap-precedes-p (h i j)
(funcall (heap-order h)
(%heap-ref h i)
(%heap-ref h j)))Code language: Lisp (lisp)5.2. sift-up
「ノードのポインタを辿る」が「添字を計算する」に変わっただけで、構造は同じです。
(defun %sift-up (h i)
(loop while (> i 0)
for p = (%heap-parent i)
while (%heap-precedes-p h i p)
do (%heap-swap h i p)
(setf i p)))Code language: Lisp (lisp)push は、要素を配列末尾に追加して sift-up を呼びます。
ポインタ版で必要だった find-node-at による追加位置の探索は、vector-push-extend が末尾に追加することで自動的に解決されます11。
(defun heap-push (h x)
(vector-push-extend x (heap-data h))
(%sift-up h (1- (heap-size h)))
h)Code language: Lisp (lisp)5.3. sift-down
「ノードが存在するかの確認」が「添字が配列の範囲内かの確認」に変わっています12。
(defun %sift-down (h i)
(loop
(let* ((l (%heap-left i))
(r (%heap-right i))
(size (heap-size h))
(best i))
(when (and (< l size) (%heap-precedes-p h l best)) (setf best l))
(when (and (< r size) (%heap-precedes-p h r best)) (setf best r))
(if (= best i)
(return)
(progn (%heap-swap h i best)
(setf i best))))))Code language: Lisp (lisp)pop は根の値を取り出し、末尾の値を根に移して sift-down します。
(defun heap-pop (h)
(assert (not (heap-empty-p h)))
(let ((result (%heap-ref h 0))
(last (vector-pop (heap-data h))))
(when (not (heap-empty-p h))
(setf (aref (heap-data h) 0) last)
(%sift-down h 0))
result))Code language: Lisp (lisp)peek は添字 0 を見るだけで O(1) です。
(defun heap-peek (h)
(assert (not (heap-empty-p h)))
(%heap-ref h 0))Code language: Lisp (lisp)5.4. 動作の確認
動作を確認します。
(let ((h (make-heap)))
(heap-push h 5)
(heap-push h 2)
(heap-push h 8)
(heap-push h 1)
(heap-push h 4)
(list (heap-pop h)
(heap-pop h)
(heap-pop h)))
;=> (1 2 4)Code language: Lisp (lisp)order に #'> を渡せば最大ヒープになります。
(let ((h (make-heap :order #'>)))
(heap-push h 5)
(heap-push h 2)
(heap-push h 8)
(heap-push h 1)
(heap-push h 4)
(heap-pop h))
;=> 8Code language: Lisp (lisp)5.5. ポインタ木版との比較
配列版では、アルゴリズムは同じで、データの持ち方だけが変わっています。
ポインタ木版:
各ノードに parent・left・right の3つのポインタが必要
find-node-at が push・pop のたびに O(log n) の走査をする
ノードごとにメモリを割り当てる(GCの対象になる)
配列版:
配列1本のみ(ポインタ不要)
親子関係は添字計算で O(1)
追加位置は fill-pointer が自動管理Code language: PHP (php)6. 優先度と値をペアにする構造
Dijkstra法では「距離と頂点」のように、優先度とそれに対応した値を分けて持つことが多いです。
order 関数でペアの先頭(優先度)だけを比較するようにします13。
(defun make-priority-queue ()
(make-heap :order (lambda (a b) (< (car a) (car b)))))
(defun pq-push (pq priority value)
(heap-push pq (cons priority value)))
(defun pq-pop (pq)
(let ((cell (heap-pop pq)))
(values (car cell) (cdr cell))))Code language: Lisp (lisp)(let ((pq (make-priority-queue)))
(pq-push pq 10 :a)
(pq-push pq 3 :b)
(pq-push pq 7 :c)
(pq-pop pq))
;=> 3, :BCode language: Lisp (lisp)6.1. 遅延削除で「探さない要素削除」
ヒープは最小値の取り出しは速いですが、内部にある特定の要素を探すのは O(n) です。
Dijkstra法では古い候補を消す代わりに新しい候補をそのまま追加し、取り出したときに古い情報なら捨てる方法がよく使われます。
この考え方を「遅延削除」と呼びます。
すぐには消さず、取り出した時点で不要なら捨てる、という方法です14。
(loop until (heap-empty-p pq)
do (multiple-value-bind (dist v) (pq-pop pq)
(when (= dist (aref dists v))
;; 取り出した時点で最短距離と一致している場合のみ処理する
(loop for (next cost) in (edges v)
do (let ((new-dist (+ dist cost)))
(when (< new-dist (aref dists next))
(setf (aref dists next) new-dist)
(pq-push pq new-dist next)))))))Code language: Lisp (lisp)取り出したときに、(< new-dist (aref dists next)) が満たされない場合には、無視して処理を進めます。
7. 各実装の比較
| 実装 | 行数 | push | pop |
|---|---|---|---|
| 未整理リスト | 22 | O(1) | O(n) |
| ソート済みリスト | 24 | O(n) | O(1) |
| ヒープ順序木(pairing heap) | 55 | O(1) | O(log n) 均し |
| 完全二分木ヒープ(ポインタ木) | 95 | O(log n) | O(log n) |
| 配列ヒープ(二分ヒープ) | 68 | O(log n) | O(log n) |
1から2は「取り出しコストを追加コストに転嫁」する変化です。
2から3は「完全な整列から必要最小限の秩序へ」という改善で、push が O(1) になります。
3から4は「木の形を完全二分木に固定」する変化で、sift-up と sift-down だけでヒープ条件を回復できるようになります。
4から5はアルゴリズムは変わらず、ポインタ木を配列に写すだけです。完全二分木の番号付けが添字計算と一致するため、ポインタをすべて添字計算に置き換えられます。
二分ヒープが速いのは「ソートより弱い秩序しか保たないから」です。
この5段階を通じて、その理由が見えてきます15。
7.1. 未整理リストのコード
(defstruct naive-pq
(data nil)
(order #'<))
(defun pq-empty-p/naive (pq)
(null (naive-pq-data pq)))
(defun pq-push/naive (pq x)
(push x (naive-pq-data pq))
pq)
(defun pq-pop/naive (pq)
(assert (not (pq-empty-p/naive pq)))
(let* ((data (naive-pq-data pq))
(order (naive-pq-order pq))
(best (reduce (lambda (a b) (if (funcall order a b) a b)) data)))
(setf (naive-pq-data pq)
(remove best data :count 1 :test #'eq))
best))Code language: Lisp (lisp)7.2. ソート済みリスト
(defstruct sorted-pq
(data nil)
(order #'<))
(defun pq-empty-p/sorted (pq)
(null (sorted-pq-data pq)))
(defun pq-push/sorted (pq x)
(let ((order (sorted-pq-order pq)))
(labels ((%insert (lst)
(cond
((null lst) (list x))
((funcall order x (car lst)) (cons x lst))
(t (cons (car lst) (%insert (cdr lst)))))))
(setf (sorted-pq-data pq)
(%insert (sorted-pq-data pq)))))
pq)
(defun pq-pop/sorted (pq)
(assert (not (pq-empty-p/sorted pq)))
(pop (sorted-pq-data pq)))Code language: Lisp (lisp)7.3. ヒープ順序木(pairing heap)
(defstruct pairing-pq
(data nil)
(order #'<))
(defun pq-empty-p/pairing (pq)
(null (pairing-pq-data pq)))
;;; ノード: (キー . 子ヒープのリスト)
(defun %make-heap-node (key &optional children)
(cons key children))
(defun %meld (a b order)
(cond
((null a) b)
((null b) a)
((funcall order (car b) (car a))
(%meld b a order))
(t
(%make-heap-node (car a)
(cons b (cdr a))))))
(defun %pairwise-meld (heaps order)
(cond
((null heaps) nil)
((null (cdr heaps)) (car heaps))
(t
(%meld (%meld (first heaps)
(second heaps)
order)
(%pairwise-meld (cddr heaps) order)
order))))
(defun pq-push/pairing (pq x)
(setf (pairing-pq-data pq)
(%meld (%make-heap-node x)
(pairing-pq-data pq)
(pairing-pq-order pq)))
pq)
(defun pq-pop/pairing (pq)
(let ((h (pairing-pq-data pq)))
(assert h)
(let ((x (car h)))
(setf (pairing-pq-data pq)
(%pairwise-meld (cdr h)
(pairing-pq-order pq)))
x)))
(defun pq-peek/pairing (pq)
(let ((h (pairing-pq-data pq)))
(assert h)
(car h)))Code language: Lisp (lisp)7.4. 完全二分木ヒープ(ポインタ木)
(defstruct heap-node
value
parent
left
right)
(defstruct pointer-heap
(root nil)
(size 0 :type fixnum)
(order #'<))
;;; size から完全二分木の n 番目のノードを求める
(defun %find-node-at (root n)
(if (= n 1)
root
(let* ((bits (integer-length n))
(path (loop for i from (- bits 2) downto 0
collect (logbitp i n))))
(reduce (lambda (node go-right)
(if go-right
(heap-node-right node)
(heap-node-left node)))
path
:initial-value root))))
(defun %sift-up/ptr (node order)
(loop while (heap-node-parent node)
for parent = (heap-node-parent node)
while (funcall order
(heap-node-value node)
(heap-node-value parent))
do (rotatef (heap-node-value node)
(heap-node-value parent))
(setf node parent)))
(defun %sift-down/ptr (node order)
(loop
(let* ((left (heap-node-left node))
(right (heap-node-right node))
(best node))
(when (and left
(funcall order
(heap-node-value left)
(heap-node-value best)))
(setf best left))
(when (and right
(funcall order
(heap-node-value right)
(heap-node-value best)))
(setf best right))
(if (eq best node)
(return)
(progn
(rotatef (heap-node-value node)
(heap-node-value best))
(setf node best))))))
(defun heap-push/ptr (h x)
(let ((new-node (make-heap-node :value x))
(size (pointer-heap-size h))
(order (pointer-heap-order h)))
(incf (pointer-heap-size h))
(if (null (pointer-heap-root h))
(setf (pointer-heap-root h) new-node)
(let* ((parent-index (floor (1+ size) 2))
(parent (%find-node-at (pointer-heap-root h) parent-index))
(go-right (evenp (1+ size))))
(setf (heap-node-parent new-node) parent)
(if go-right
(setf (heap-node-right parent) new-node)
(setf (heap-node-left parent) new-node))
(%sift-up/ptr new-node order))))
h)
(defun heap-pop/ptr (h)
(assert (pointer-heap-root h))
(let* ((root (pointer-heap-root h))
(result (heap-node-value root))
(size (pointer-heap-size h))
(order (pointer-heap-order h)))
(if (= size 1)
(setf (pointer-heap-root h) nil)
(let ((last (%find-node-at root size)))
(setf (heap-node-value root) (heap-node-value last))
(let ((parent (heap-node-parent last)))
(if (eq (heap-node-right parent) last)
(setf (heap-node-right parent) nil)
(setf (heap-node-left parent) nil)))
(setf (heap-node-parent last) nil)
(%sift-down/ptr root order)))
(decf (pointer-heap-size h))
result))Code language: Lisp (lisp)7.5. 配列ヒープ(二分ヒープ)
(defstruct heap
(data (make-array 16 :adjustable t :fill-pointer 0))
(order #'<))
(defun heap-size (h)
(fill-pointer (heap-data h)))
(defun heap-empty-p (h)
(zerop (heap-size h)))
;;; 補助: 添字計算
(defun %heap-parent (i) (floor (1- i) 2))
(defun %heap-left (i) (1+ (* 2 i)))
(defun %heap-right (i) (+ 2 (* 2 i)))
;;; 補助: 要素アクセスと交換
(defun %heap-ref (h i)
(aref (heap-data h) i))
(defun %heap-swap (h i j)
(rotatef (aref (heap-data h) i)
(aref (heap-data h) j)))
(defun %heap-precedes-p (h i j)
(funcall (heap-order h)
(%heap-ref h i)
(%heap-ref h j)))
(defun %sift-up (h i)
(loop while (> i 0)
for p = (%heap-parent i)
while (%heap-precedes-p h i p)
do (%heap-swap h i p)
(setf i p)))
(defun %sift-down (h i)
(loop
(let* ((l (%heap-left i))
(r (%heap-right i))
(size (heap-size h))
(best i))
(when (and (< l size) (%heap-precedes-p h l best)) (setf best l))
(when (and (< r size) (%heap-precedes-p h r best)) (setf best r))
(if (= best i)
(return)
(progn (%heap-swap h i best)
(setf i best))))))
(defun heap-push (h x)
(vector-push-extend x (heap-data h))
(%sift-up h (1- (heap-size h)))
h)
(defun heap-pop (h)
(assert (not (heap-empty-p h)))
(let ((result (%heap-ref h 0))
(last (vector-pop (heap-data h))))
(when (not (heap-empty-p h))
(setf (aref (heap-data h) 0) last)
(%sift-down h 0))
result))
(defun heap-peek (h)
(assert (not (heap-empty-p h)))
(%heap-ref h 0))Code language: Lisp (lisp)- 二分ヒープは J. W. J. Williams が 1964年にヒープソートのデータ構造として発表しました。論文は “Algorithm 232: Heapsort” として Communications of the ACM に掲載されています。同年、Robert W. Floyd がより効率的なヒープ構築アルゴリズムを発表しました。 – Binary heap – Wikipedia
- Dijkstra法は優先度付きキューなし(配列実装)では O(V²) ですが、二分ヒープを使うと O((V+E) log V) になります。Fibonacci Heap を使うとさらに O(E + V log V) まで改善できますが、定数項が大きく実用上は二分ヒープが多く使われます。 – Time and Space Complexity of Dijkstra’s Algorithm – GeeksforGeeks
removeの:test #'eqは、オブジェクトの同一性(ポインタが同じか)で比較します。数値にはeqlの方が安全です。同じ値が複数ある場合にeqだと意図しない要素が削除されることがあるため、数値を扱うキューでは:test #'eqlを使うほうが確実です。 – CLHS: Function REMOVE – LispWorks- この
pushの動作は挿入ソートの1ステップと同じ構造です。挿入ソートはすでに整列済みのリストへの追加には向いていますが、全体の整列には O(n²) かかります。優先度付きキューとして使うと、n 回の push で O(n²) になります。 - 「親 <= 子」を保つ最小ヒープは最小値を、「親 >= 子」を保つ最大ヒープは最大値を根に置きます。Dijkstra法には最小ヒープ、ヒープソートには最大ヒープが使われます。この記事の実装では
order関数を切り替えるだけで両方に対応できます。 – Binary heap – Wikipedia integer-lengthは二進数で表現するのに必要なビット数を返す Common Lisp の組み込み関数です。(integer-length 7)は 3 を返し(7 = 111₂ で3ビット)、(integer-length 4)は 3 を返します(4 = 100₂)。 – Function INTEGER-LENGTH – CLHSrotatefは Common Lisp の標準マクロで、複数の場所の値を左ローテーションします。(rotatef a b)は一時変数なしで a と b を入れ替えます。各サブフォームを1回だけ評価するため、(let ((tmp a)) (setf a b) (setf b tmp))より安全です。 – Macro ROTATEF – CLHS- sift-down が sift-up より実装が複雑になるのは、子が最大2つあるためです。sift-up では比較相手が親1つだけですが、sift-down では左右の子のうち優先度が高い方を選んでから交換する必要があります。子が1つの場合(最下段の左端)も考慮する必要があり、これが
(< l size)や(< r size)による範囲チェックに対応しています。 - C++ の
std::priority_queueや Python のheapqはいずれも配列ベースの二分ヒープで実装されています。ポインタ木版はアルゴリズムの理解には適していますが、実用ライブラリとしては使われません。 - この 0-indexed の添字規約が最も広く使われていますが、1-indexed にすると親が
floor(i / 2)、左の子が2i、右の子が2i + 1と計算式がやや単純になります。どちらを使うかは実装の好みによります。 – Binary heap – Wikipedia vector-push-extendは:adjustable tと:fill-pointerを持つベクタにだけ使えます。fill-pointer が配列の容量に達するとadjust-arrayを呼んで自動拡張します。拡張時の新しいサイズは実装依存ですが、多くの処理系では2倍程度に拡張されます。 – Function VECTOR-PUSH-EXTEND – CLHSheap-sizeは(fill-pointer (heap-data h))を返します。fill-pointerはベクタのアクティブな要素数を返す関数で、vector-push-extendで追加するたびに1増え、vector-popで取り出すたびに1減ります。 – 17.5. Fill Pointers – CLtL2pq-popがvaluesで複数の値を返し、呼び出し側がmultiple-value-bindで受け取るのは Common Lisp の多値機能です。戻り値をコンスセルに包まずに済むため、余分なメモリ割り当てを避けられます。- 遅延削除を使うと、キューに古い候補が残り続けるため、最悪の場合キューのサイズが辺の数 E に比例して大きくなります。Dijkstra法では各辺について最大1回 push するので、キューの最大サイズは O(E) です。 – Dijkstra’s algorithm – Wikipedia
- ヒープソートは配列版ヒープを利用したソートアルゴリズムで、計算量は最悪・平均ともに O(n log n) です。ただし、キャッシュ局所性が低いため、クイックソートよりも実測では遅いことが多く、多くの処理系ではクイックソートの最悪ケース対策のフォールバックとして組み込まれています。 – Heapsort – HandWiki