SoftMatcha 2は、1兆規模のテキストコーパスから「ほぼ同じ表現」を0.1秒台で探せる検索システムです。
完全一致だけでなく、単語の置換・挿入・削除を許した照合ができるため、ベンチマーク汚染の検出に使えます。内部ではディスクアクセスを前提に設計されたsuffix arrayと、コーパスの統計を使った枝刈りで候補爆発を抑えています。意味が大きく変わるような言い換えは拾えないため、「ヒットしたら証拠になる」が「ヒットしなければ汚染なし」とは言い切れない点に注意が必要です。
1. SoftMatcha 2とAIベンチマーク
LLMの性能を測るベンチマークテスト。
ただし、事前学習データに問題そのものが入っていては、かんたんに答えられてしまいます。
これをベンチマーク汚染といいます。
そこで、学習データの中に、テスト内容が含まれていない確認する必要があるのですが、ここで困るのが、完全一致だけ見ても本質が取り逃がされがちなことです。
少し言い換えられていたり、句読点が変わっていたり、途中が抜けていたりするからです。
SoftMatcha 2は、その「ちょっとズレた一致」を、トリリオン(1兆)規模のコーパスに対してサブ秒で探すことを狙ったシステムです。
その仕組みの特徴は、ディスク(特にHDD)の制約を正面から受け入れたデータレイアウトと、コーパスの統計を使った動的な枝刈りにあります。
- Softmatcha 2 Demo
- softmatcha/softmatcha2: A fast and soft pattern search for trillion-scale corpora.
- [2602.10908] SoftMatcha 2: A Fast and Soft Pattern Matcher for Trillion-Scale Corpora
1.1. ベンチマーク汚染とは?
「benchmark contamination(ベンチマーク汚染)」とは、モデル評価に使う問題文・正解・解説などが、事前学習データに含まれてしまうことです。
汚染があると、スコアが上がっても「能力が上がった」のか「既視感で答えた」のかが分かりにくくなります。
LLM評価の信頼性に直結します。
SoftMatcha 2の論文では、この汚染を「既存手法では見つからなかった例まで含めて」見つけられることを実用例として示しています1。
1.2. なぜ厳密一致だけでは足りないのか
「含まれる」と言っても、完全一致とは限りません。
引用、転載、言い換え、要約、フォーマット変換でも起きるからです。
たとえば、次のような差分があると、厳密一致は簡単に外れます。
「The capital of Japan is Tokyo.」
「Japan’s capital city is Tokyo.」
意味はほぼ同じですが、文字列としては一致しません。
句読点や余分な語の挿入削除でも同様です。
ここに置換・挿入・削除を許す検索が効きます。
2. SoftMatcha 2がやりたい検索
SoftMatcha 2は「完全一致検索」だけの道具ではありません。
クエリに対して、次のゆるさ(許容)を入れた検索をします。
つまり、「単語が少し変わっても」「間に何か入っても」「一部が抜けても」拾える検索です。
ただし、ここで注意が必要です。
SoftMatcha 2は「文章の意味ベクトルを近い順に並べる」タイプの検索とは少し違います。
内部ではあくまで順序を保つパターン照合(pattern matching)で、そこに「許される編集(置換・挿入・削除)」を入れています。
2.1. 「似ている」の中身はどこまでか
実装(公開リポジトリ)を見ると、デフォルト設定は GloVe(glove-wiki-gigaword-300)で、 fastText や Transformer 系など複数の embedding/tokenizer backend を使う設定も用意されています。
GloVe(Global Vectors)は単語分散表現、fastTextはサブワード(subword)も見る単語分散表現です2。
つまり「置換」は、単語同士の類似度に基づいて候補を作れる設計になっています。
ここで「万能な意味理解」を期待しすぎると外します。
近い単語への置換や、表記ゆれ・軽い言い換えには強い一方で、長い推論や大幅な言い換えを完全に吸収する仕組みではありません。
ここは使いどころの見極めが必要です。
2.2. ベンチマーク汚染以外の用例探索
「ある表現がどういう文脈で使われているか」を大規模コーパス上で素早く確かめる用途にも、SoftMatcha 2は使えます。
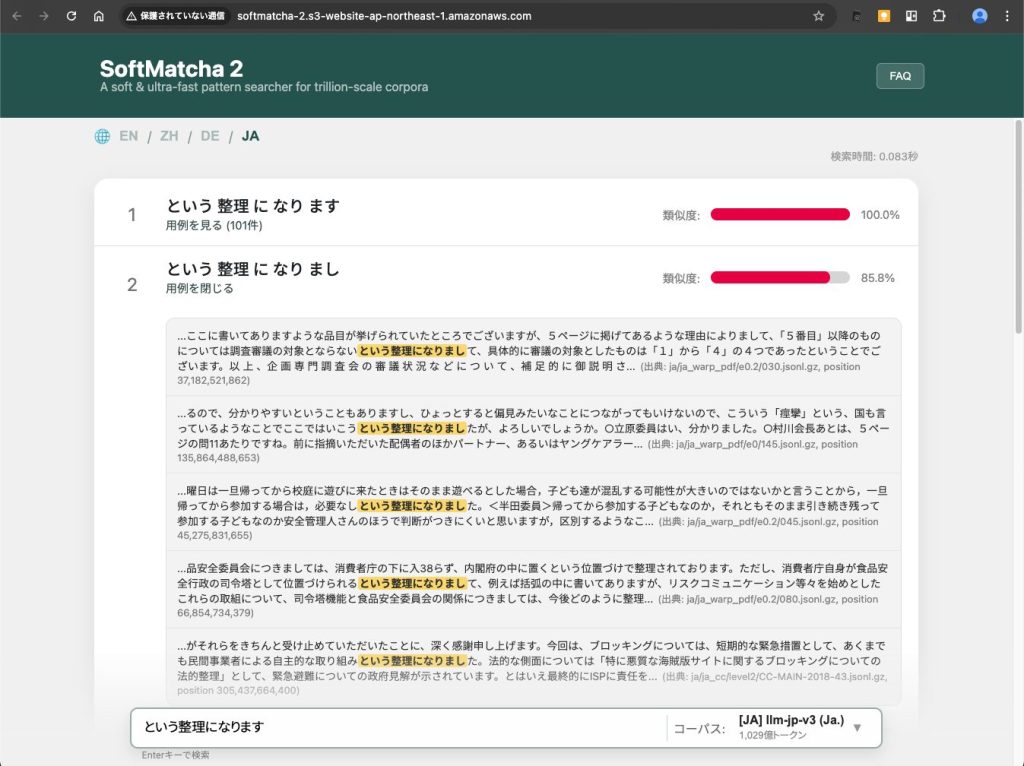
たとえば、SNSで「試しに『〜という整理になります』というフレーズで検索してみたところ、ヒットした用例のほとんどが法律・行政関連の文書に集中していた」という投稿がありました3。
ChatGPTがこの表現を好んで使うのは、事前学習データに占める法曹・官僚文書の比率が影響している可能性があります。
3. disk-aware suffix array と dynamic pruning
SoftMatcha 2の説明を読むと、主役は2つです。
1つ目が「ディスクに優しい(disk-aware)厳密照会」、
2つ目が「コーパス統計に基づく動的な枝刈り(dynamic corpus-aware pruning)」です。
3.1. suffix array(接尾辞配列)をディスク前提で使う
suffix array(接尾辞配列)は、文字列の全接尾辞を辞書順に並べて、部分文字列検索を速くする索引です4。
理屈だけ聞くと教科書的ですが、トリリオン規模で効かせるには「どの順番で、どの塊を、ディスクから読むか」が支配的になります5。
そこで disk-aware design が出てきます。
HDDはランダムアクセスが遅く、順次読みが相対的に速いです。
この前提に合わせて、索引のレイアウト(配置)とアクセス手順を設計すると、同じsuffix arrayでも体感が変わります。
3.2. dynamic corpus-aware pruning(動的・コーパス依存の枝刈り)
置換・挿入・削除を許すと、素直に候補を列挙した瞬間に候補数が爆発します(指数的に増えます)。
ここは探索問題のいつもの壁です。
SoftMatcha 2は、探索の途中で「この枝を伸ばしても、実データ上ほぼ当たらない」を切ります。
ポイントは、一般的なヒューリスティックではなく、コーパスの統計的性質を使って爆発を抑える、と書いているところです。
将棋でたとえるなら、「全手を同じ深さまで読む」のではなく、局面の手触りから悪そうな手を早めに切る、に近いです。
ただし切り方が雑だと正解を落とすので、実データに根拠を置く、という発想になります。
4. 擬似コードで見るSoftMatcha 2の探索(イメージ)
論文と公開情報から読み取れる範囲で、「どういう流れの探索か」を擬似コードに落とします。
細部は実装依存ですが、骨格はこの形だと理解しやすいです。
# SoftMatcha 2(実装に寄せた“逐次展開+都度existence check”)の擬似コード例
# 入力:
# pat: 検索したいトークン列(長さ L、ただし L <= 12)
# SA : disk-aware suffix array インデックス(prefix の存在確認が高速)
# sim(t, u): 単語類似度(embedding に基づく)
# top_similar(t): t の近傍トークン上位 N
# パラメータ例:
# MAX_INS_PER_STEP = 4 # 1ステップ当たりの挿入上限
# MUL_DEL < 1.0 # 削除のペナルティ(乗算)
# MUL_INS < 1.0 # 挿入のペナルティ(乗算)
# softmin(a, b): “小さい方に寄る”滑らかな最小(例: log-sum-exp 系)
構造体 状態:
q # いま構築中の候補トークン列(クエリ側の仮生成列)
score # 累積スコア(softmin と multiplier で更新)
hits # SA 側の「この prefix が現れる範囲」など(存在確認の結果)
関数 refine_hits(SA, q):
# q がコーパス内に prefix として存在するかを suffix array で絞る
# 存在しないなら None、存在するなら hits(範囲やポインタ)を返す
...
関数 ソフト検索(pat, SA, K):
初期状態 st0:
q = []
score = 1.0
hits = refine_hits(SA, q) # 空 prefix は常に存在
候補集合 C = { st0 }
# pat を左から順に処理(逐次)
for i in 0..L-1:
t = pat[i]
次候補集合 C2 = 空集合
# 1) 置換(substitution): t を近い単語候補に置き換えて q を伸ばす
for st in C:
for u in top_similar(t):
st2.q = st.q + [u]
st2.hits = refine_hits(SA, st2.q)
if st2.hits が None: continue # ここで即枝刈り(存在しないなら捨てる)
loc_sim = sim(t, u)
st2.score = softmin(st.score, loc_sim)
C2 に st2 を追加
# 2) 削除(deletion): pat 側の t をスキップ(q は伸ばさない)
for st in C:
st2.q = st.q
st2.hits = st.hits # q が変わらないのでそのまま
st2.score = st.score * MUL_DEL
C2 に st2 を追加
# 3) 挿入(insertion): q 側にトークンを挿入(最大 MAX_INS_PER_STEP 回)
# 重要: 挿入は「それっぽいものを何でも」ではなく、
# SA の hits から “この prefix の次に実際に出るトークン候補” を列挙して限定するイメージ
C3 = C2
repeat ins_step in 1..MAX_INS_PER_STEP:
C4 = C3
for st in C3:
for v in next_token_candidates_from_hits(SA, st.hits):
st2.q = st.q + [v]
st2.hits = refine_hits(SA, st2.q)
if st2.hits が None: continue
st2.score = st.score * MUL_INS
C4 に st2 を追加
C3 = C4
# 4) 爆発を抑えるため、スコアや同一 q の重複排除などで上位だけ残す
C = topM_dedup(C3) # M は実装都合の上限(例: ビーム幅に相当)
# 最後に、C のうち “完全に確定した候補列 q” を score で並べて返す
# hits から実際の出現位置(文書ID等)を取り出して返してもよい
return topK(C, K)Code language: PHP (php)読んでいて大事なのは、(2) と (3) の往復です。
候補生成を少し進めたら即座に exact lookup で「この方向は生きているか」を確かめ、死んでいれば深追いしません。
これができるのは exact lookup が速いからです。
5. 限界と、使うときに気になる点
良い話ばかりだと判断を誤るので、気になりそうな点も書きます。
5.1. 更新が多いデータには向きにくい
suffix array系の索引は、頻繁な更新(追加・削除・差し替え)に弱いのが一般的です6。
SoftMatcha 2も「巨大でほぼ静的なコーパス」に強く寄った設計だと捉えるのが安全です。
5.2. インデックスが重い
インデックスが数倍に膨らむのは、速度と引き換えです。
大規模コーパスだと「3倍未満」と書かれていても、絶対量は巨大です。
HDD前提の設計だとしても、容量・構築時間・配置は現実の制約になります。
5.3. 「意味的類似」は万能ではない
置換は単語類似度に寄っているので、文全体の意味が飛ぶような言い換えや、長距離の推論を伴う同値変形は別問題です。
汚染検証に使う場合でも、「見つかったら強い証拠」「見つからないから汚染がない、とは言い切れない」という姿勢が必要です7。
- SoftMatcha 2は実験においてFineWeb-Edu(1.4兆トークン)で既存手法より大幅に低い検索遅延を実現しました。既存手法にはinfini-gram、infini-gram mini、初代SoftMatchaが含まれます。 – SoftMatcha 2: A Fast and Soft Pattern Matcher for Trillion-Scale Corpora
- GloVeは単語の共起統計から学習する単語分散表現で、コーパス全体の文脈を活用します。fastTextは文字n-gramを含むため形態素が豊富な言語に有効で、訓練データにない語でも表現を生成できます。 – Word2Vec, GloVe, and FastText, Explained
- moraさん: 「ChatGPTがよく使う「〜という整理になります」という日本語に違和感があったので、最近話題の SoftMatcha 2 で用例検索してみたらヒヤリング文章にばかりマッチした。https://t.co/YGZG1RAYKF」 / X
- 接尾辞配列は1990年にManberとMyersが接尾辞木の省スペース代替として導入しました。接尾辞木は実用上20n バイトを必要としますが、接尾辞配列は3〜5倍少ない空間で済みます。 – Suffix Arrays: A New Method for On-Line String Searches
- 接尾辞配列を用いた検索は二分探索により O(m log n) 時間で可能ですが、各比較に O(m) 時間を要します。最長共通接頭辞情報を追加保存することで検索時間を O(m + log n) に改善でき、この情報は線形時間で計算可能です。 – Optimal Exact String Matching Based on Suffix Arrays
- 接尾辞配列の構築には比較ベースのソートで O(n² log n) 時間かかりますが、SA-ISアルゴリズムなど高度な手法では線形時間構築が可能です。ただし動的な更新には対応しにくい構造です。 – Suffix array – Wikipedia
- ベンチマーク汚染の検出手法は大きく2つに分類されます。マッチングベースの手法は文字列照合や統計を使い、比較ベースの手法はモデルの振る舞いを分析します。どちらも完全ではなく、組み合わせが推奨されます。 – Benchmark Data Contamination of Large Language Models: A Survey