- 再帰呼び出しはコールスタックにフレームを積み上げ、戻りがけに計算する構造をとるため、深くなるとスタックオーバーフローが起きる。
- リスト生成は再帰の痕跡をコンスセルとしてヒープに残す操作で、コールスタックの代わりに明示的なデータとして計算の構造を保持する。
- ループと配列はスタックもコンスセルも生成せず、ノイマン型アーキテクチャの連続メモリ構造に沿って動くため、メモリ消費が一定に保たれる。
- 動的計画法は再帰の暗黙なスタックをヒープ上のデータ構造に刻み直す手法で、リスト生成はその最もシンプルな形にあたる。
1. 再帰が深いとスタックオーバーフロー
プログラミングを習いたての頃は、繰り返し処理はループで書くのがわかりやすいです。
Common Lispでも、loop for i from 1 to nと書けば、 n 回繰り返す処理が動きます。
(loop for i from 1 to 5
do (print i))Code language: Lisp (lisp)しばらくすると、再帰関数で書いた方が設計がすっきりすることに気づきます。
再帰を使うと、問題の定義がそのままコードになる感覚があります。
;; f(n) = f(n-1) + f(n-2)
(defun fib (n)
(cond ((= n 0) 0)
((= n 1) 1)
(t (+ (fib (- n 1))
(fib (- n 2))))))Code language: Lisp (lisp)ところが、再帰で書いたコードは、大きな数値だとメモリや計算時間を浪費してしまいます。
しばしば、スタックオーバーフローで停止してしまいます。
1.1. リストの生成コスト・走査コスト
同じことをリストについても感じます。
リストは、(list 1 2 3)と生成できる、Common Lispの基本的なデータ構造です。loopには、リストを操作しやすい構文があり、loop for n in lstと書けば、リストの各要素について繰り返し、collect節を使えば、かんたんに新しいリストを生成できます。
(defun odd-numbers (lst)
(loop for n in lst
when (oddp n)
collect n))
(odd-numbers (list 5 6 10 20 6 25))
;=> (5 25)Code language: Lisp (lisp)小さな関数ごとに中間データをリストに積み上げて返せば、問題の流れを追いやすくなります。
しかし、リストもデータ数が大きくなるとメモリや走査時間がかかってきます。
再帰もリストも、Common Lispの基本操作なのですが、気をつけて使わないとすぐに「非効率」なコードになってしまいます。
2. 同じ計算の3つの書き方
3. リスト生成
Common Lispでは、繰り返し処理の書き方には、3つのスタイルがあります。
ループ、再帰、リストです。
まずは、 n 〜 1 までの整数のリスト生成する rev-iota 関数をそれぞれ作ってみます。
;; (rev-iota/loop 10)
;;=> (10 9 8 7 6 5 4 3 2 1)
(defun rev-iota/loop (n)
(loop for i from n downto 1
collect i))
;; (rev-iota/rec 10)
;;=> (10 9 8 7 6 5 4 3 2 1)
(defun rev-iota/rec (n)
(cond
((zerop n) nil)
(t (cons n (rev-iota (1- n))))))
;; (rev-iota/map 10)
;=> (10 9 8 7 6 5 4 3 2 1)
(defun rev-iota/map (n)
(mapcar (lambda (_)
(declare (ignore _))
(1+ (decf n)))
(make-list n)))Code language: Lisp (lisp)ループは制御構造が見やすく、再帰はコンスセルの構築がわかりやすいです。
マップ版は、いったん n 個のリストを作ってから、内部変数 n を更新して要素を値として変換しています。
3.1. 繰り返し計算
あるいは、関数fに1からnまでの整数を適用して合計する処理を、三通りで書いてみます。
(defun f (x)
(+ (* 2 x) 5))
;; ループ版
;; (compute-by-loop 10 #'f) ;=> 165
(defun compute-by-loop (n func)
(loop for i from 1 to n
sum (funcall func i)))
;; 再帰版
;; (compute-by-rec 10 #'f) ;=> 165
(defun compute-by-rec (n func)
(cond ((zerop n) 0)
(t (+ (funcall func n)
(compute-by-rec (1- n) func)))))
;; リストの畳み込み版
;; (compute-by-list 10 #'f) ;=> 165
(defun compute-by-list (n func)
(reduce #'(lambda (acc x)
(+ acc (funcall func x)))
(iota n)
:initial-value 0))Code language: Lisp (lisp)それぞれ内部でやっていることは違いますが、三つともちゃんと同じ答えを返します。
4. 再帰が止まる問題
ただし、n が大きな数字になると問題が発生します。
compute-by-loopは同じ n でも問題なく動くのに、compute-by-recだと止まってしまいます。
(compute-by-loop 10000000 #'f)
;==> 100000060000000
(compute-by-rec 100000 #'f)
;=> Control stack exhausted
;; Control stack exhausted (no more space for function call frames).
;; This is probably due to heavily nested or infinitely recursive function
;; calls, or a tail call that SBCL cannot or has not optimized away.Code language: Lisp (lisp)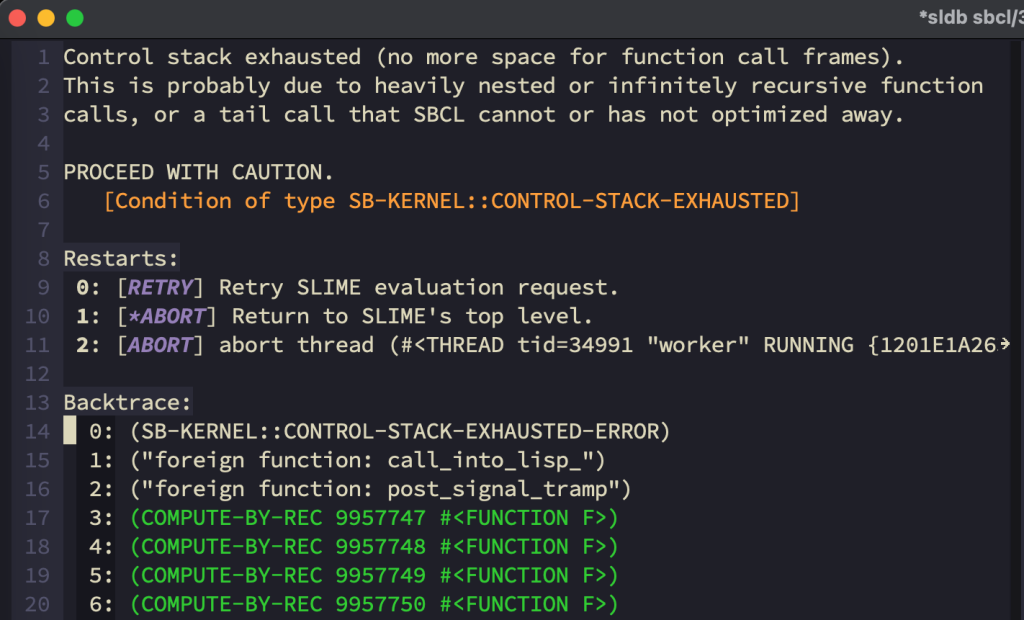
「Control stack exhausted」というエラーは、「制御スタックを使い切った」という意味です。
4.1. コールスタックに記録される情報
関数呼び出しでは、関数がまだ終わっていないまま次の関数を呼ぶので、「戻ってきたあと何をするか」を覚えておく必要があります。
そのため、1回呼ぶたびに引数や途中の計算状態、戻り先などを入れたスタックフレームがコールスタックに積まれます。
(compute-by-rec 4 #'f)
スタックの積み上げ
rec(4)
rec(3)
rec(2)
rec(1)
rec(0) → 0 ← 基底ケース、ここで折り返す
戻りがけに + で畳み込む
(+ (f 1) 0) = 12
(+ (f 2) 12) = 21
(+ (f 3) 21) = 32
(+ (f 4) 32) = 45Code language: PHP (php)nのぶんだけフレームが積まれて、基底ケースで折り返し、戻りがけに+で計算結果を得ます。
計算が終わるとスタックは解放されて消えます。
ただし、深く呼ぶほど未完了の処理が増え、スタック上のメモリ使用量も増えます。
OSがプロセスに割り当てるスタック領域は数MB程度しかなく、メモリが残っていても、わりと早くスタックオーバーフローになります。
4.2. 再帰は暗黙にリストを生成している
Common Lispでは、再帰とリストは対応しています。
compute-by-recとrev-iotaを並べると、同じ構造になっています。
; compute-by-rec: 戻りがけに + で畳み込む
(+ (f 4) (+ (f 3) (+ (f 2) (+ (f 1) 0))))
; rev-iota: 戻りがけに cons で組み立てる
(cons 4 (cons 3 (cons 2 (cons 1 nil))))Code language: Lisp (lisp)再帰パターンの (rev-iota/rec 4)の、スタックの動きを追うと、こうなります。
スタックの積み上げ
rev-iota(4)
rev-iota(3)
rev-iota(2)
rev-iota(1)
rev-iota(0) → nil ← 基底ケース
戻りがけに cons で組み立てる
(cons 1 nil) = (1 . nil)
(cons 2 (1)) = (2 . (1 . nil))
(cons 3 (2 1)) = (3 . (2 . (1 . nil)))
(cons 4 (3 2 1)) = (4 . (3 . (2 . (1 . nil))))compute-by-recでは戻りがけに合計を計算して、スタックフレームを解放して消えるのに対して、rev-iotaはスタックフレームの代わりにコンスセルをヒープに残します。
つまり、リストとは、積み上げたスタックの痕跡がコンスセルとしてヒープ領域に刻まれたデータです。
また、再帰呼び出しに計算コストがあるのは、スタックフレームを積み上げる、という「暗黙のリスト生成」があるからです。
4.3. リストや再帰は自然数の定義と同型
リストや再帰呼び出しは数えられ、その長さは自然数です。
ここで思い出すのが、ペアノの公理です。
ペアノの公理では、自然数を 0 とsuccessor関数の再帰で定義します。
0, S(0), S(S(0)), S(S(S(0))), ...あるいは、ノイマンは自然数を空集合の集合で定義しました。
∅, {∅}, {∅, {∅}}, {∅, {∅}, {∅, {∅}}}, ...コンスセルのリストは、これと同じ構造です。
nil, (1 . nil), (2 . (1 . nil)), ...リストが再帰が同型なのは、どちらも「作る」操作を共有しているからです。
リストは、nilから始まり、consのたびに一つ大きくなる。
再帰も、呼び出すごとに一段ずつ積み上がります。
5. ループは状態を上書きする
一方、loopでは、左から右へ一方向に進みながら、その場で反復して合計します。
compute-by-loopの動きはこうです。
i=1 → i=2 → i=3 → i=4
↓ ↓ ↓ ↓
f(1) f(2) f(3) f(4)
\ \ \ \
+─────+─────+──────= 165変数 iと累積値は順次上書きして更新され、それぞれの計算が終わった瞬間に、その途中の情報は累積値に吸収されて消えます。
スタックフレームもコンスセルも作らないので、nがいくら大きくなってもメモリ消費は一定です。
5.1. リストは作り、配列は区切る
C言語のコードでは、ループと配列が主流です。
「配列」も、リストのような複数のデータを格納するデータ構造ですが、再帰的に作るのではなく「確保」します。
(make-array 4)
;=> #(0 0 0 0)Code language: Lisp (lisp)先にメモリ領域を確保して、インデックスで区切るだけです。
連続するデータ領域に縛られるため、リストほど柔軟なデータ構造を作ることはできませんが、生成やアクセスには無駄がありません。
5.2. ノイマン型アーキテクチャのフラットな連続メモリ構造
ループや配列が効率的なのは、ノイマン型アーキテクチャに密着した形だからです。
フォン・ノイマンは、フラットな連続メモリにプログラムもデータも並べる、という現代のコンピュータの基本構造を作りました。
RAMの連続したアドレスにコードやデータを並べ、CPUはその命令を順番に実行します。
ループはその命令の流れそのもので、配列はそのメモリ配置そのものです。
GOTOはアドレスへのジャンプ、ポインタはアドレスそのものです。
一方、Common Lispのリストや再帰は、数学的な帰納的構造に密着しています。
フラットなノイマン型のハードウェア上で、数学的な入れ子構造を動かしています。
そのために、変換コストがかかります。
だから、Common Lispでは、リストや再帰が使いやすいものの、計算コストが高くなっているのです。
6. シリアル構造と音声言語
ノイマン型のシリアルな設計は、どこから来たのでしょうか。
人間が、情報を記録してきた媒体をたどってみると、その根っこは音声言語にあるように見えます。
それが、巻物、写本、印刷物、パンチカード、磁気テープ、そしてRAMのアドレス列と移り変わっても、すべて連続的な列構造、つまりシリアルなシーケンスです。
シリアルデータ構造には、転送しやすい性質があります。
音声は空気の振動一本、電信はワイヤ一本で情報を伝達できます。
これらは、音声言語の線形性を空間に写したものから始まっています。
音声は時間軸上のシリアルデータで、同時に二つの音を出せない。
だから、人間の言語は本質的に線形で、文は一方向に流れる。
言語で思考を記録しようとしたとき、その線形性が記録媒体にも反映されました。
チューリングマシンも無限テープにシンボルを並べる設計で、計算の理論的基礎からしてシリアルです。
そして、フォン・ノイマンがそれをハードウェアに実装したとき、連続アドレスのRAMとプログラムカウンタという形になりました。
6.1. 木構造と自然
一方、Lispのコードはその木構造です。
(+ (* 2 x) (- y 3))というS式を視覚的に読むと、コードが木として一度に把握できます。
+
/ \
* -
/ \ / \
2 x y 3木構造も、自然界によく見られます。
まさに、樹木は幹が枝に分かれ、枝がさらに枝に分かれる構造になっています。
これらは、葉脈、血管、河川のデルタ、稲妻、肺の気管支など、自然界では同じパターンが縮尺を変えて繰り返されるフラクタルで満ちています。
生命がこの構造を選んだのは、少ない情報を「種」として複雑な形を作れるからです。
DNAという有限の情報から、再帰的な成長ルールで巨大な構造が展開されています。
木構造は視覚的・空間的な把握に対応しています。(+ (* 2 x) (- y 3))というS式は、言語化しようとすると「まず掛け算をして、次に引き算をして、最後に足す」という変換しなければならない。
木構造での思考は少ない情報に圧縮できますが、言語化するにはいったん連続構造に展開しなければならないのです。
6.2. 操作型思考と構造型思考の螺旋
ここまでを整理すると、二つの思考パターンの対比が見えてきます。
- 構造型思考は、問題をそのまま見ます。
フィボナッチの定義がそのままコードになる。
再帰の定義、リストの生成、S式の木構造。
問題の形とコードの形が一致しているから、認知的負荷が低い。 - 操作型思考は、実行の形に合わせます。
「nをどう更新するか」「配列のどのセルをどの順序で埋めるか」を考える。
問題の構造から離れて、ハードウェアの動きに近い形に翻訳します。
手続き型プログラミングは、「まずこれをして、次にこれをして」という、操作型の考え方です。
プログラミングの初心者が手続き型から入りやすいのは、自然言語の思考パターンに近いからでしょう。
シンプルで速く、問題の構造が見えていなくても、「とりあえず動く」。
問題の「構造」を理解するようになると、それを時間軸ではなく構造軸で考えようになります。
これが、リストや再帰によるプログラミングです。
リストやmapcarで解くようになり、さらに再帰で設計するようになると、問題の帰納的な構造がそのままコードになる感覚を得られます。
しかし、計算効率が必要になると、再び手続き型に戻ります。
Common Lispでも、計算アーキテクチャに近い形に最適化する必要があります。
たとえば、その手法の一つが動的計画法(DP)です。
6.3. DPはその刻み直し
compute-by-listでは、再帰をいったんリストとしてヒープに生成してから、reduceで畳み込みました。
; rev-iota でリストを作る(ヒープに刻む)
(4 3 2 1)
; reduce で畳み込む
(f 4) + (f 3) + (f 2) + (f 1) + 0 = 165Code language: Lisp (lisp)コールスタックを使わずにすむ代わりに、リスト全体をメモリに持ちます。
再帰の暗黙なスタックを、明示的なヒープ上のデータ構造に置き換えました。
これは、DPの原型です。
リストから配列への最適化はその延長です。
; リスト:コンスセルがヒープに散らばる
(4 3 2 1)
; 配列:連続メモリに詰める
#(1 2 3 4)Code language: Lisp (lisp)配列は、連続メモリに詰めることで、必要なメモリ領域
さらに「今必要な値だけ」に絞り込むと、更新変数になります。
フィボナッチなら直前の二値だけ持てばよい。
(defun fib-compact (n)
(if (< n 2)
n
(loop for i from 2 to n
with a = 0 and b = 1
do (psetf a b b (+ a b))
finally (return b))))Code language: Lisp (lisp)再帰の痕跡をどこにどう刻むか、という選択の段階です。
| 形式 | 痕跡の場所 | 特徴 |
|---|---|---|
| 再帰 | コールスタック(消える) | 構造が見えやすい、深さに制限 |
| リスト | ヒープ(残る) | 明示的、メモリを使う |
| 配列 | ヒープ(連続) | アクセスが速い |
| 更新変数 | レジスタ/ローカル変数 | メモリ最小、構造が見えにくい |
Common Lispでリストと再帰から始めるのは、計算の構造をコードに見せたまま考えられるからです。
効率が必要になったとき、その構造を理解した上でアーキテクチャに近い形に寄せていく。
その判断が場当たりにならないのは、何を最適化しているかが最初から見えているからです。