1. 音声収録をAIでカットする
収録した音声をそのまま出すのは難しいです。
言い直し、間、録り直し前の音……
これらを全部手動でカットすると、時間がかかります。
特に「ここはバッサリ切った方がいい」という決断を自分でするのは、意外と迷います。
そこで、 Zoom クラウドレコーディングで収録した文字起こしを ChatGPT に渡し、Audacity のラベルでカット表を生成して、編集してみました。
- Zoom クラウドレコーディングで録音すると、クラウドに VTT 形式の文字起こしが自動生成されます。
- その VTT を ChatGPT に渡してカット表をラベルファイル形式で生成し、Audacity で読み込んで波形を見ながら手動で微調整します。
- あとはラベルごとに複数ファイルで書き出して、ffmpeg と Python で結合するという流れです。
| 役割 | ツール |
|---|---|
| 収録・文字起こし | Zoom クラウドレコーディング + AI Companion |
| カット判断(たたき台) | ChatGPT |
| 波形確認・微調整 | Audacity(ラベル機能) |
| 書き出し・結合 | Python + ffmpeg |
1.1. Zoom有料プランのレコーディング
音声の収録には、Zoom 有料プランのクラウドレコーディングを使いました。
理由は、
- Zoom はノイズ除去が収録側で処理されており、別途フィルタをかけなくても話し声がきれいに録れます。
- クラウド処理なので録音中のローカルマシン負荷が低く、収録しながら別の作業をしていても動作が重くなりにくいです。
- AI Companion による文字起こしと要約が自動で生成される点です。
Zoomアプリには、ミーティングを開催しなくても、レコーディング機能があります。
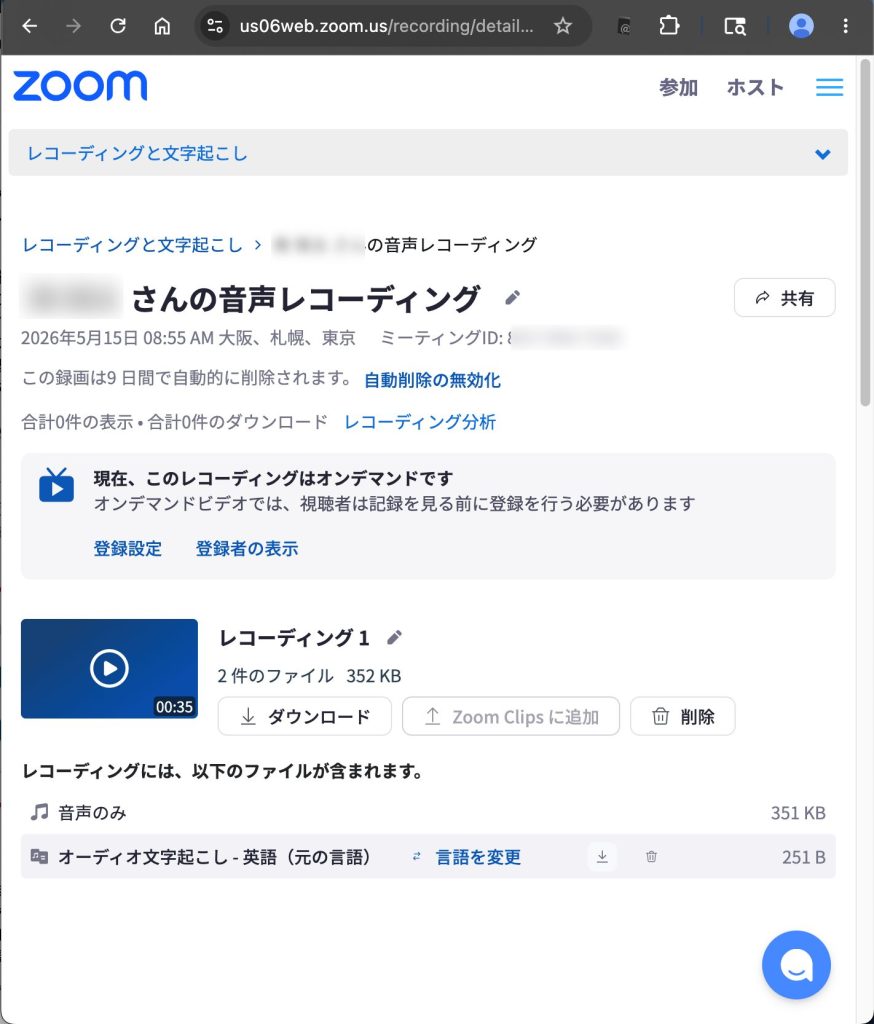
収録が終わると、クラウド上に音声ファイルと VTT 形式の文字起こしが保存されるので、そのまま次のステップに使えます1。
1.2. VTT ファイルとは
VTT は WebVTT(Video Text Tracks) という、動画の字幕用として設計されたテキスト形式で、各セリフに開始・終了の時刻が付いています2。
Zoom が出力する VTT は、
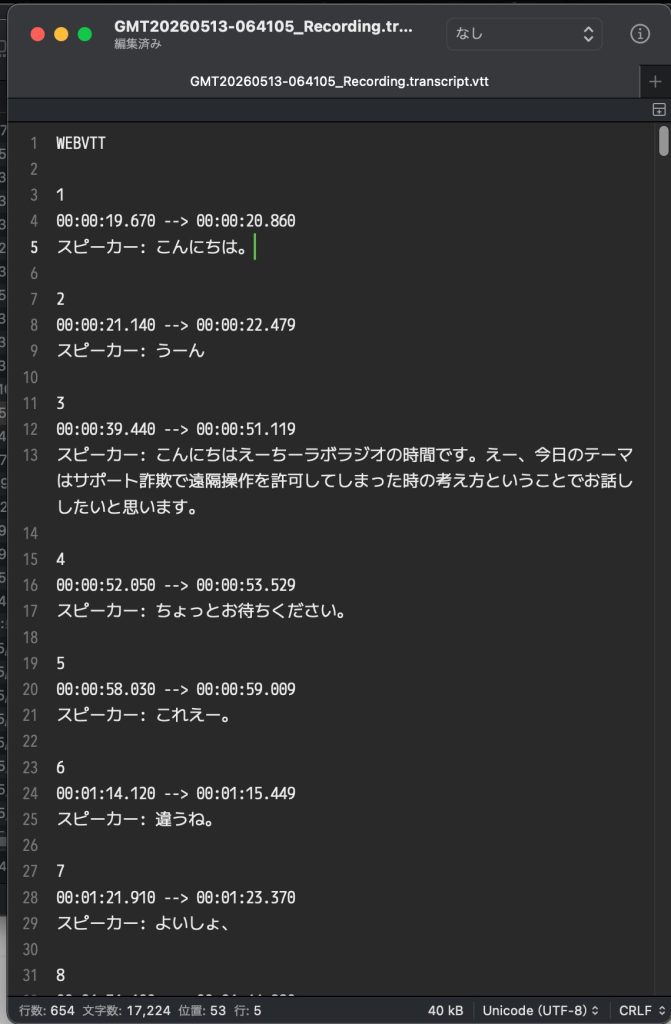
WEBVTT
1
00:01:47.880 --> 00:01:57.919
スピーカー: こんにちは。
ちいラボラジオの時間です。
今日のテーマは...
2
00:01:58.010 --> 00:02:01.319
スピーカー: 最近インターネットを見ているとCode language: CSS (css)話者名と発話ごとのタイムスタンプが入っているので、AI に渡して「どこで何を話しているか」を時刻ベースで判断させられます3。
もし、自分で録音した音声ファイルなら、Google AI Studioなどで音声を読み込ませて、VTTを作っておくとよいです。
2. ChatGPT にカット表を作らせる
VTT ファイルをそのまま ChatGPT に貼り付け、次のようなプロンプトを渡します。
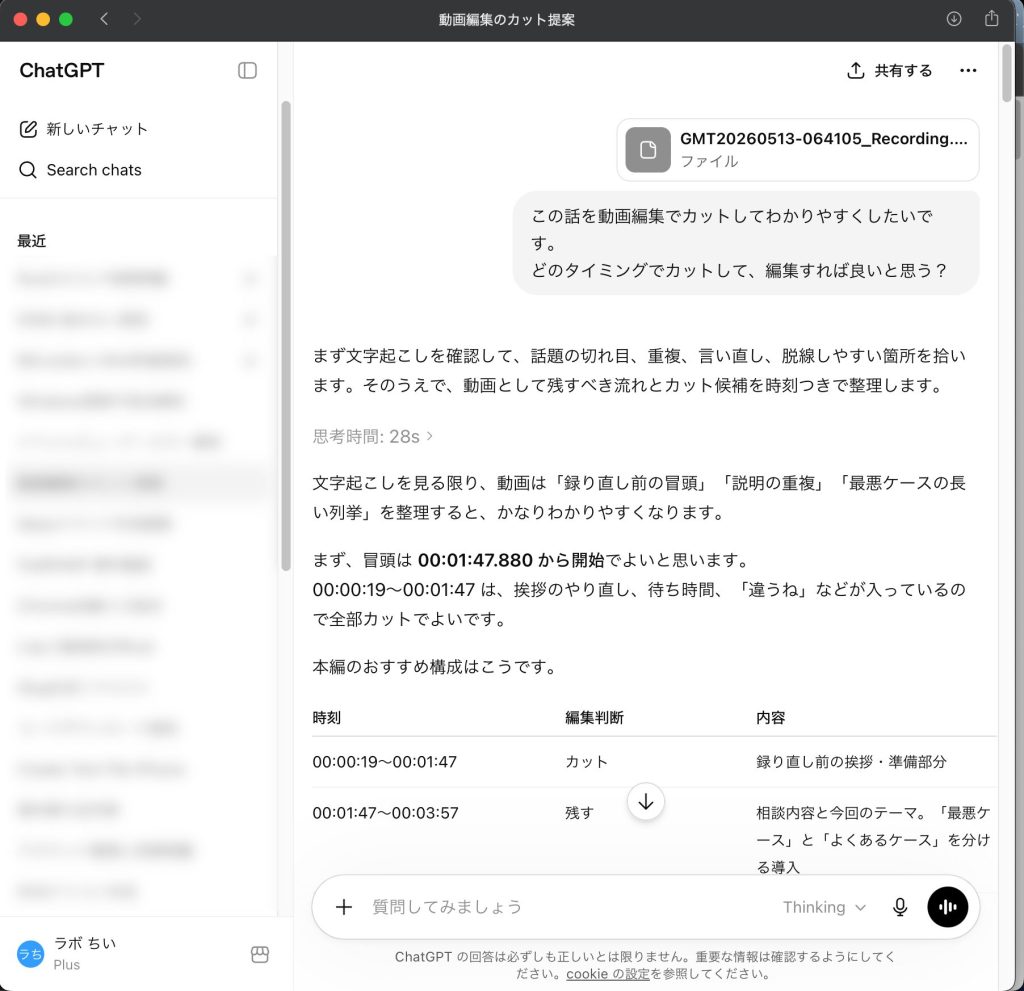
以下は音声収録の VTT 字幕ファイルです。
この内容を見て、10分のYouTube動画用に残すべき区間をまとめたラベルファイルを作ってください。
出力形式は Audacity のラベル形式(タブ区切り)でお願いします。
開始秒[タブ]終了秒[タブ]ラベル名
- 言い直しや準備中の発話はカット
- 話のまとまりごとに KEEP_XX_ラベル名 という形でまとめる
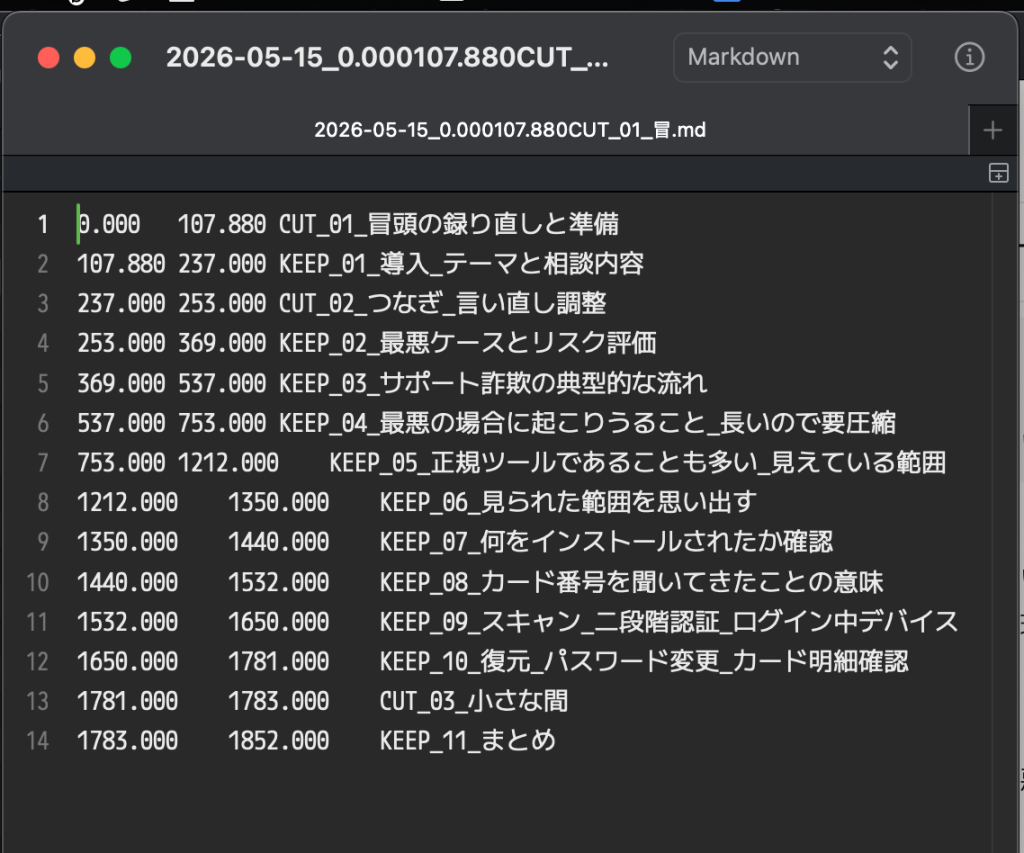
[ここに VTT の内容を貼る]Code language: CSS (css)出力されたのがこのようなファイルです。
107.880 117.919 KEEP_01_テーマ提示
169.150 203.270 KEEP_02_相談内容_遠隔操作と不安
218.220 237.480 KEEP_03_考え方_最悪ケースとよくあるケースを分ける
337.670 370.010 KEEP_04_リスク評価_ゼロイチで考えない
...Code language: CSS (css)開始秒・終了秒・ラベル名がタブ区切りで並ぶ、Audacity のラベルファイル形式で結果を生成します4。
2.1. Audacity でラベルを読み込む
音声変換ソフト Audacity には、ラベル表を読み込む機能があります。
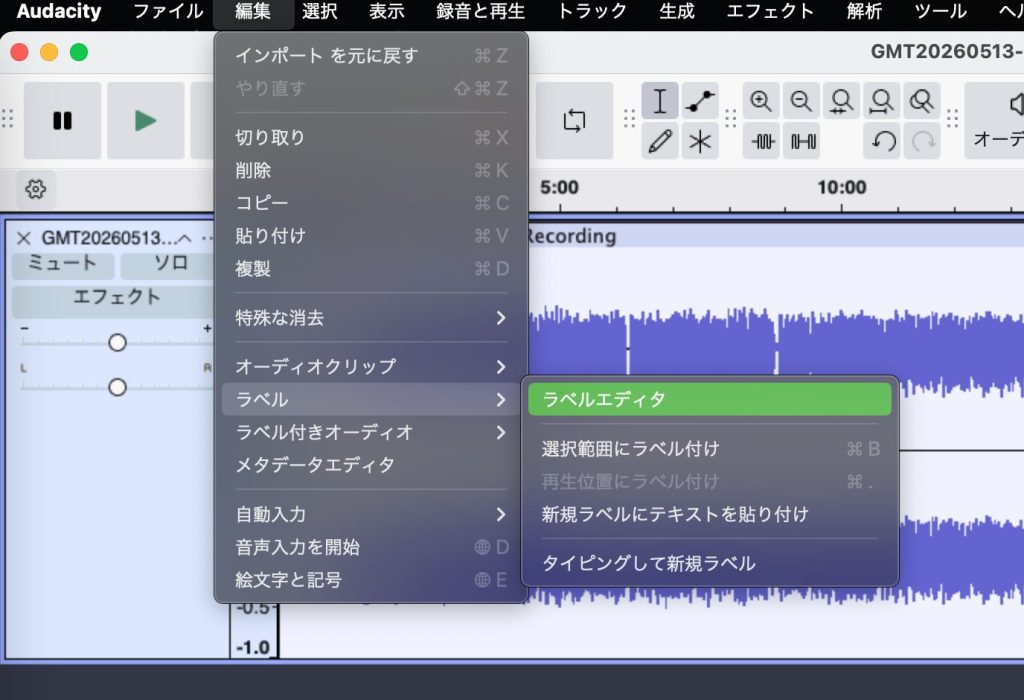
まず、Audacity に音声ファイルを読み込み、それからメニューの ファイル > 取り込み > ラベル からこのテキストファイルを読み込みます。
タイムライン上に自動でラベルが表示されます。
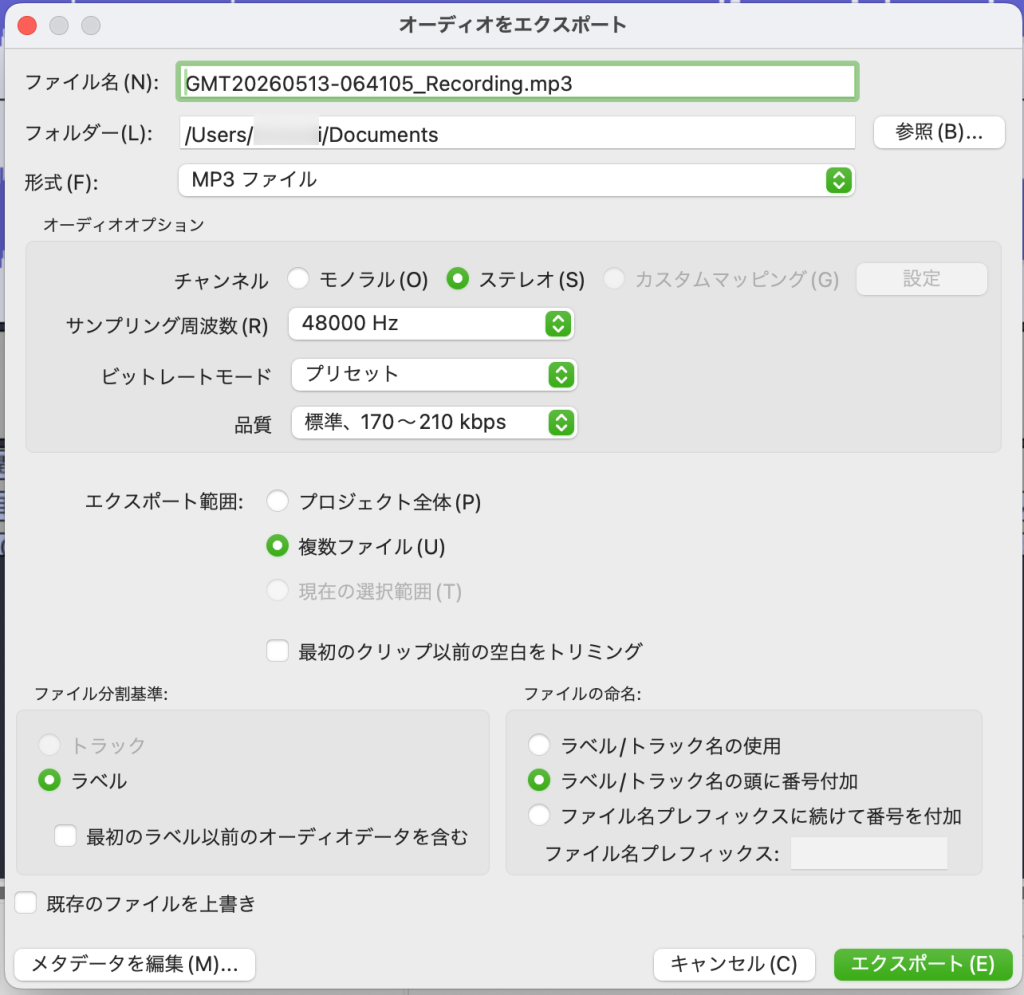
そして、ラベルを基準に、分割して音声ファイルを書き出します。ファイル > オーディオを書き出す から「複数ファイル」を選び、ファイル分割基準を「ラベル」に設定します。
このときファイル命名は「ラベル/トラック名の頭に番号付加」にしておくと、あとで並び順が明確になります5。
3. Audacityでのラベルの調整
AI が生成するカット表は、タイムスタンプが数秒ずれていることがあります。
しかし、「おおよそここからここまで」という目安として、ラベルの位置を波形と一緒に目で確認しながら、ずれているところを手動で微調整することもできます。
ラベルをクリックしてからスペースキーを押すと、その区間だけが再生されるので、どの区間が残るかを確認できます。
書き出す前に各 KEEP 区間を順番に試聴しながら位置を確認できます。
3.1. Python と ffmpeg で結合する
複数に分割された音声ファイルは、動画編集ソフトに取り込むときに並べて使ってもよいですが、結合しておくと通しで聴きやすいです。
ターミナル上で音声ファイルの編集するために ffmpeg を使いました。
macOS なら Homebrew で入れられます。
brew install ffmpegCode language: Bash (bash)あとは、PythonスクリプトでCLIのffmpegを操作し、フォルダ内の音声ファイルを一括結合しました。
from pathlib import Path
import subprocess
input_dir = Path(".")
output_file = "combined.mp3"
mp3_files = sorted(input_dir.glob("*.mp3"))
if not mp3_files:
raise FileNotFoundError("mp3 ファイルが見つかりませんでした。
")
list_file = input_dir / "filelist.txt"
with list_file.open("w", encoding="utf-8") as f:
for mp3 in mp3_files:
f.write(f"file '{mp3.resolve()}'\n")
subprocess.run([
"ffmpeg", "-y",
"-f", "concat",
"-safe", "0",
"-i", str(list_file),
"-c:a", "libmp3lame",
"-b:a", "192k",
output_file
], check=True)
print(f"結合しました: {output_file}")Code language: Python (python)単なるコピー結合だと境界で音が乱れたり再生時間表示がずれたりすることがあるため、-c:a libmp3lame で再エンコードしました6。
話し声の編集なら、再エンコードによる音質の変化は気にならない範囲に収まります。
4. やってみてわかったこと
生成AIによるカット編集の利点は、「バッサリ切る判断を任せられる」という点でした。
自分では「ここは残した方がいいかも」と迷ってしまう箇所でも、AI はあっさりカット対象に入れてきます。
それをたたき台にして「やっぱり残す」と判断するのは自分でできますし、その方向で考えると判断が速くなります。
編集方針を変えたくなったときに、ラベルファイルだけ修正して Audacity に読み込み直せばいいので、何度でも同じ編集を作り直せます7。
- VTT 形式の文字起こしを出力するには、Zoom ウェブポータルの詳細クラウド録画設定で「音声トランスクリプト」を有効にしておく必要があります。AI Companion によるスマートレコーディング(チャプター自動分割・要約など)は Pro 以上の有料プランで追加料金なしで利用できます。 – AI Companionでスマートレコーディングを使用する
- WebVTT は W3C(World Wide Web Consortium)が策定した標準仕様で、HTML5 の
<track>要素と組み合わせて使う字幕・キャプション用フォーマットです。SRT(SubRip)形式を基に設計されており、主要ブラウザすべてがネイティブでサポートしています。 – WebVTT: The Web Video Text Tracks Format - Zoom 標準の日本語文字起こし精度は、一般的な会話で 70〜80% 程度とされています。専門用語や固有名詞が多い場面では誤認識が増えます。カット編集のたたき台として使う分には支障ありませんが、書き起こし原稿として使う場合は別途校正が必要です。 – Zoom会議の文字起こし方法比較
- Audacity のラベルファイルはタブ区切りのプレーンテキスト(.txt)で、開始秒・終了秒・ラベル名の順に記述します。開始秒と終了秒が同じ場合はポイントラベル、異なる場合はリージョンラベルとして読み込まれます。テキストエディタやスプレッドシートで編集してから再インポートすることも可能です。 – Importing and Exporting Labels – Audacity Manual
- 複数ファイル書き出しでは、最上位にあるラベルトラックのみが書き出し対象になります。また、ミュートしたトラックは書き出されません。「最初のラベル以前のオーディオデータを含む」のチェックをオフにすると、KEEP ラベルより前の音声を書き出しから除外できます。 – Exporting multiple audio files – Audacity Manual
- ffmpeg の concat demuxer を使って
-c copyでコピー結合すると、AAC/M4A では DTS(Decoding Time Stamp)の不連続によるタイムスタンプのずれが発生することがあります。再エンコードするとこれを回避できます。ファイルの仕様(コーデック・サンプルレート・ビットレート)が完全に一致している場合はコピー結合が安全ですが、Audacity から書き出した複数ファイルを混在させる場合は再エンコードの方が安定します。 – How to Merge and Concatenate Videos with FFmpeg - Audacity のラベルファイルはテキストエディタで直接編集できます。秒数を修正してから再インポートするだけで、波形を触らずにカット位置を変えられます。カット判断の履歴をバージョン管理しておけば、編集意図を記録しながら作業を進めることもできます。 – Label Tracks – Audacity Manual