1. AIの「数値演算」
ChatGPTやClaudeに質問すると、数秒で回答が返ってきます1。
その裏側では、コンシューマー向けのゲームPCには載らないような大型の計算機が、想像を超える規模の数値演算を走らせています。
なぜ、それほどの計算が必要なのか、そしてなぜGPUや電力の需要が世界規模で跳ね上がっているのかを、順を追って見ていきます。
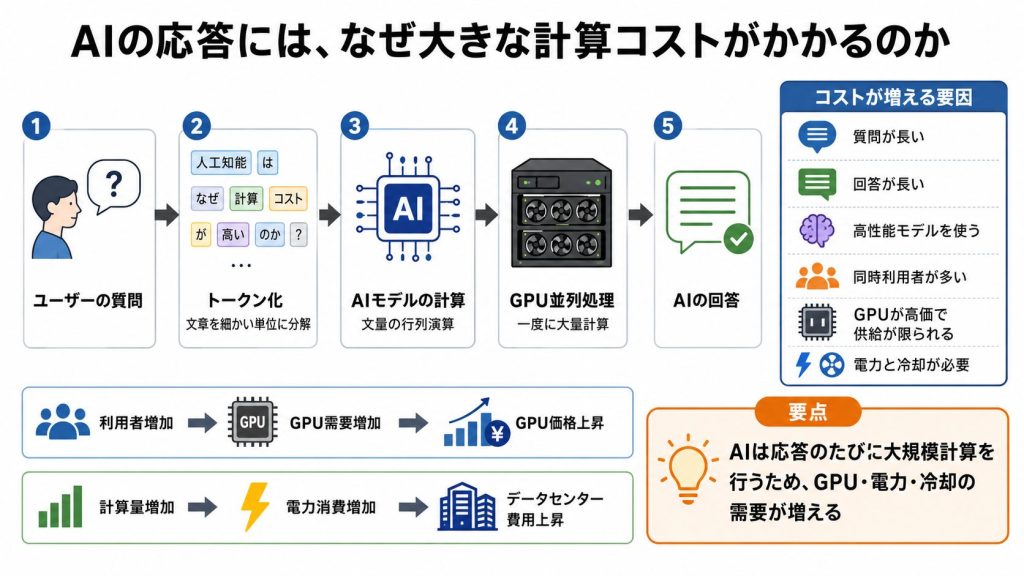
1.1. AIは「文章」をそのまま読んでいない
AIは、人間が読むような形でテキストを扱っていません。
入力された文章は、まず「トークン」と呼ばれる最小単位に分解されます2。
「東京タワーの高さは?」であれば、「東京」「タワー」「の」「高さ」「は」「?」のように細かく切り、それぞれを数値に変換します。
AIが実際に処理するのはこの数値の列です。
1.2. 1回の回答に30時間?
変換された数値列は、「ニューラルネットワーク」の内部を通過します。
ニューラルネットワークは、何百億個ものパラメータを持つ、数式の集合体です。
入力トークンごとに「次に来る単語の確率」を計算し続けます。
この計算処理の実体は、「行列演算」です。
数千×数千の数値を掛け合わせ、足し合わせる操作を、1回の返答の中で数兆回も繰り返します。
あの試算によれば、GPT-3のような今となっては小さい規模の言語モデルでも、1回推論させるだけで、350兆回以上の浮動小数点演算が走ります3。
これは、通常のCPUで順番に処理しようとすると、30時間以上もかかる計算量に相当します。
1.3. なぜGPUでなければならないか
ただ、この行列計算は、情報量は多くてもルールはシンプルです。
「単純な掛け算を膨大な数、同時に実行する」ことだからです。
これは、「複雑な処理を高速に順番に実行する」CPUには苦手な分野です。
GPUは、もともと映像描画のために開発された半導体で、数千から数万個の小さな演算コアを並べた構造を持ちます。
たとえば、NVIDIAのA100 GPUには512個のテンソルコアがあり4、それぞれが4×4の行列積を1サイクルで完了させます。
つまり、CPUでは数十ステップかかる計算を、GPUは一気に、しかも並列実行できます。
いわば、3Dゲームで緻密に光の影や反射、流体の動きなどを計算して映像を作るのと、ニューラルネットワークで計算して答えを作るのは、「似ている」計算なのです。
3Dゲームでは、物理世界をシミュレーションするのにGPUを使い、生成AIでは、神経ネットワークをシミュレーションするのにGPUを使っています。
AI推論においてGPUが不可欠な理由は、ここにあります。
2. 計算量はどこで増えるか
同じ言語モデルでも、その計算コストはリクエストの内容によって変動します。
GPT系モデルの推論では、パラメータ数をp、入出力トークン数をnとしたとき、おおよそ「2×n×p」回の浮動小数点演算が必要です。
- :入出力トークン数
- :総パラメータ数
- :モデルの隠れ次元数(hidden dimension)
コンテキストが短い(が小さい)うちは第1項が支配的で、が大きくなると項が効いてきます。
2.1. 生成AIの「脳が大きくなる」
また、高性能モデルほどパラメータ数 p が桁違いに多くなります。
大規模言語モデルにとって、パラメータ数は、いわば「脳の大きさ」です。
パラメータが増えるほど行列のサイズが拡大し、同じ入出力でも演算量が跳ね上がります。
GPT-3は1750億パラメータで5、最新のGPT-5.5はパラメータ数は非公表になっていますが、規模が大きいはずです。
| 年月 | モデル | 総パラメータ数 | 開発元 |
|---|---|---|---|
| 2021/06 | GPT-J 6B | 6 B | EleutherAI |
| 2021/10 | GPT-Neo 2.7B | 2.7 B | EleutherAI |
| 2022/02 | GPT-NeoX 20B | 20 B | EleutherAI |
| 2022/07 | BLOOM 176B | 176 B | BigScience(国際研究連合) |
| 2023/02 | LLaMA 1 65B | 65 B | Meta |
| 2023/07 | LLaMA 2 70B | 70 B | Meta |
| 2024/04 | LLaMA 3 70B | 70 B | Meta |
| 2024/07 | LLaMA 3.1 405B | 405 B | Meta |
| 2024/12 | DeepSeek-V3 | 671 B | DeepSeek |
| 2025/07 | Kimi K2 | 1,000 B | Moonshot AI |
| 2026/04 | DeepSeek-V4 Pro | 1,600 B | DeepSeek |
| 2026/04 | Kimi K2.6 | 1,000 B | Moonshot AI |
2.2. 質問文やチャットが長くなるとコストが増える
一つは、生成AIを使う人数や頻度、長さが増えることです。
生成AIを同時に使う利用者が増えれば、同じGPUを複数のリクエストで奪い合うことになります。
ほかの人の処理待ち時間を減らして、スループットを維持するにはGPU自体の数を増やすしかありません。
これがGPU需要急増の直接的な原因です。
また、単純に言えば、質問が長いほど入力トークン数が増え、行列演算の量も増えます。
つまり、nが2倍になれば演算量も2倍になります。
nは、入力トークンだけでなく、出力トークンも含めます。
回答が長くなるとトークンを1つ生成するたびに同等の計算を繰り返すため、コストも線形に増えていきます。
3. GPUはすぐには作れない
AIサービスの利用が増え、データセンターはより多くのGPUを調達しようとしています。
ところが、GPUの製造は半導体ファウンドリの能力に依存しており、先端GPUの増産には少なくとも数ヶ月から数年単位の設備投資が必要です。
需要が急に跳ね上がっても供給がすぐには追いつかず、価格が上昇します。
メタは、2025年末までに130万台のGPUを運用する計画を実施し6、マイクロソフトも同年度に800億ドルをAIインフラに投じました。
こうした大手の先行投資が、市場全体の調達コストを押し上げています。
3.1. 電力と冷却が次のボトルネック
また、GPUが集積するほど、電力消費と発熱の問題が表面化します。
NVIDIAの最新世代チップであるBlackwell(GB200)は、GPT-3のトレーニングに使われたA100の7倍近い電力を消費します。
AIを処理するサーバーラックは従来のサーバーとは桁違いの電力密度になるため、専用の高電力データセンターと液体冷却設備が必要になります。
IEAのレポートによれば、世界のデータセンターによる電力消費は2024年の約4,150億kWh(415 TWh)から2030年には約9,450億kWh(945 TWh)へと倍増が見込まれます7。
Gartnerの予測では、AI最適化サーバーの電力消費は2025年から2030年の間にほぼ5倍になります8。
電力の調達競争はすでにデータセンターの立地選定に影響しており、再生可能エネルギーが豊富な地域や電力インフラが安定している地域への投資が加速しています。
4. 高コストの構造
利用者が増えるとGPU需要が増え、供給が追いつかず価格が上昇し、データセンターの調達コストが上がります。
一方で計算量が増えると電力消費が増え、冷却コストと設備投資が増え、データセンターの運用コストが上がります。
AIへの問い一つひとつが、こうした連鎖の末端にあります。
「なぜAIサービスが高コストになるのか」「なぜGPUが品薄になるのか」は、突き詰めれば「行列演算が数兆回必要だから」という事実に帰着します。
利用者が増えてAIが賢くなるほど、インフラへの負荷も拡大し続ける——これが現在進行形で起きていることです。
- 2026年2月時点でChatGPTの週間アクティブユーザーは9億人に達し、1日あたり25億件以上のプロンプトが処理されています。 – ChatGPT Statistics (May 2026)
- 日本語は英語と異なり、1文字あたり1〜3トークンを消費する傾向があります。英語では1単語がおおよそ1トークンに対応するため、同じ内容を日本語で入力すると消費トークン数が多くなります。 – ChatGPT(チャットGPT)トークンの完全ガイド
- a16zのレポートでは、パラメータ数をp、入出力トークン数をnとしたとき、1回の推論に必要な演算量はおおよそ「2×n×p」FLOPsと算出されています。GPT-3(1750億パラメータ)をトークン長n=1000で推論する場合、約350兆回の演算が必要になります。 – Navigating the High Cost of AI Compute
- A100 GPUのテンソルコアは4×4の行列積(128 FLOP相当)を1サイクルで完了させます。FP16精度では312 TFLOPS、TF32精度では156 TFLOPSの理論性能を持ちます。 – Navigating the High Cost of AI Compute
- OpenAIが2020年5月に発表した論文「Language Models are Few-Shot Learners」で公開された数値です。GPT-2の1.5億パラメータから約100倍に拡大されました。 – OpenAI Presents GPT-3, a 175 Billion Parameters Language Model
- メタの設備投資計画の詳細と各社のGPU調達動向については、Global X Japanのレポートで確認できます。xAIも350〜400億ドルを投じてGPU100万個規模のスーパーコンピューターを拡張する計画を公表しています。 – AIには迅速な電力供給が必要
- IEA「Energy and AI」(2025年)レポートの数値です。2030年の電力消費は日本の総電力消費量をわずかに上回る規模とされています。 – Energy and AI – Executive Summary
- Gartnerの予測では、AI最適化サーバーの電力消費は2025年の93 TWhから2030年には432 TWhへと増加するとされています。同期間にデータセンター全体の消費量も448 TWhから980 TWhへ倍増する見通しです。 – Gartner、データセンターの電力需要は2025年に16%増加し、2030年までに2倍になるとの予測を発表