- アダプティブ思考は、従来の「Extended thinking」に相当する機能で、推論の深さを工数(Effort)で調整できるようになりました。
- アダプティブ思考をオフにすると、工数をHighにしても推論は動きません。
- Sonnet 4.5に相当するような資料整理や文章生成は、Sonnet 4.6 Mediumがちょうどよさそうでした。
- ちなみに、内部で消費される推論トークンは出力の10〜30倍になることもあり、特に会話履歴の蓄積で後半ほど1ターンの消費が急増するので、履歴の蓄積をリセットしてトークン消費を節約することも大事です。
1. 「工数(Effort)」と「アダプティブ思考(Adaptive Thinking)」
Claude Opus 4.8の新機能が追加されました。
同時に、Claude Sonnet も 4.6にアップデートされ、入力欄の右下に見慣れないUIが増えていました。
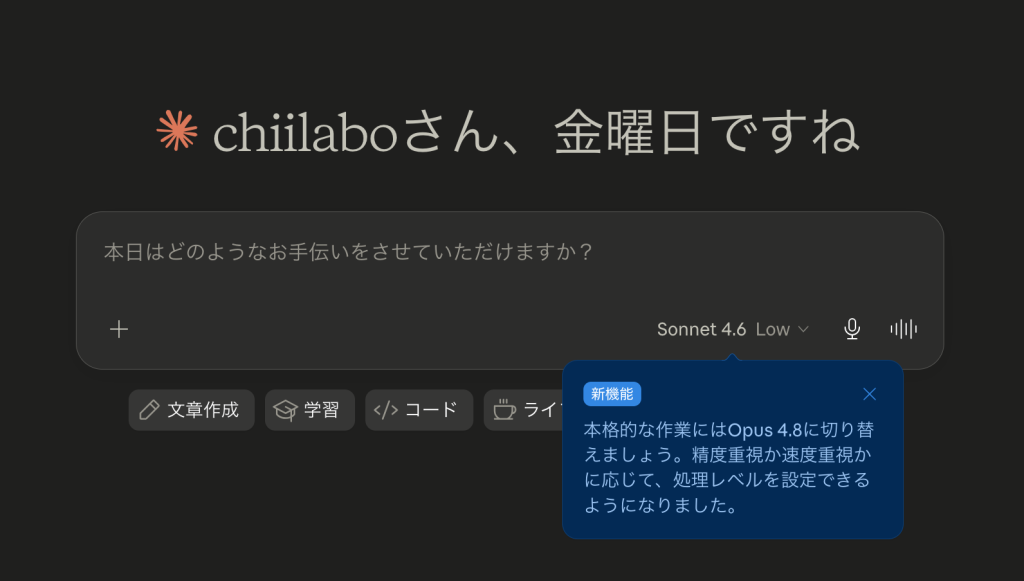
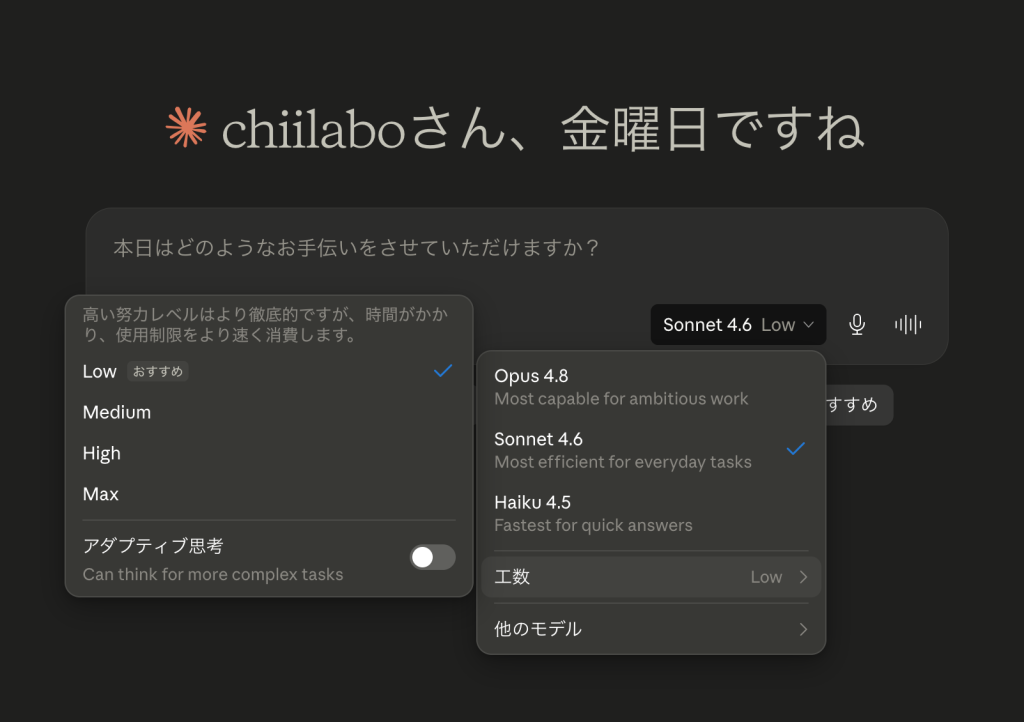
「工数」の選択肢と「アダプティブ思考」のスイッチです。
Low・Medium・High・Maxという4段階と、オン・オフを切り替えるスイッチ。
Sonnet 4.5までにはなかった組み合わせです。
最初は「Highにすればより賢く動く、アダプティブはそのさらに上のブーストかな」と思ったのですが、設定の意味を調べたところ、思い込みとは違う構造だったようです。
1.1. 内部推論の有効化と強度
Sonnet 4.5では、「Extended thinking」という項目があり、オン・オフを選択していました。
Claudeが応答を生成する前に内部で推論ステップを踏む機能です。
表示される出力とは別にトークンとして消費されます。
ただ、推論の深さについては、システムが自動に切り替えていました。
一方、「アダプティブ思考」では、その推論の深さもユーザーが選べるようになりました。
それが、「工数(Effort)」です。
アダプティブ思考をオンにすると、工数が推論の深さを制御するようになります。
Anthropicの公式ドキュメントによれば、Highではほぼ常に推論が走り、Lowではシンプルな問題でスキップする可能性があるとされています1。
逆に言うと、アダプティブ思考をオフにすると、工数をHighにしようとMaxにしようと、内部推論チェーンは起動しません2。
ただし、工数は、傾向を制御するパラメータで、問題が複雑だと、Lowに設定していてもClaudeは自分の判断で推論します3。
UIの並びから「工数が強さで、アダプティブはそのさらに上のブースト」だとイメージしたのですが、実際には、アダプティブ思考が「元栓」、工数はその強さという関係のようです4。
1.2. 資料分析と文章生成での使い分け
私は、ふだんClaudeのProプランで、1週間のレート制限がちょうど100%ぐらいです。
なので、同じように使うにはトークン消費を意識する必要があります。
実際の作業での計測値を示します。
ClaudeのProプランで、単一セッション内で数学についての文章を、完成させたときのデータです。
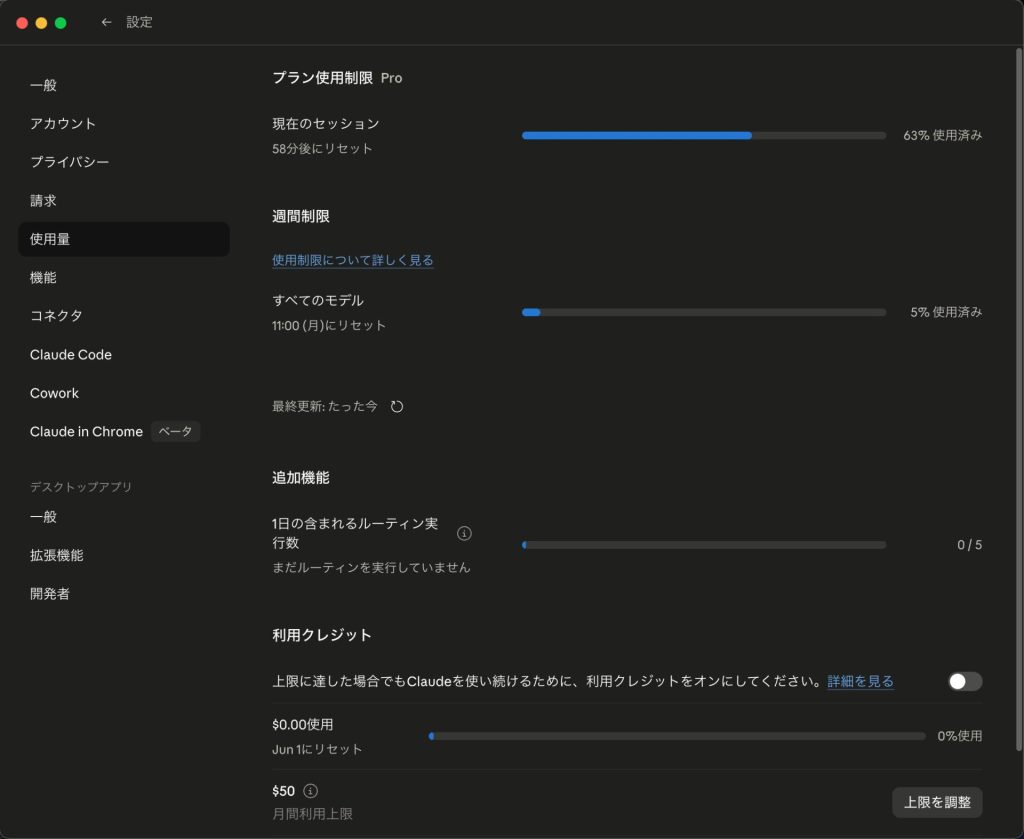
| 項目 | 実測値・内容 |
|---|---|
| 記事テーマ | 圏論とプログラミング設計 |
| 記事規模 | 本文約4,500語 |
| 使用モデル | Claude Sonnet 4.6 |
| 工数 | Medium |
| アダプティブ思考 | ON |
| 往復回数(実測) | 約35〜40ターン |
| セッション消費(5時間枠) | 0% → 63%(作業前後) |
| 週間消費 | 0% → 5% |
| 週換算 | 同規模の作業を週約20本こなせる計算 |
やり取りの往復が約40ターンということで、やや推敲が多い作文でした。
この消費量だと、1週間でこの規模の作業を20本こなせる計算になります。
ただ、5時間のセッション消費63%で、長い会話を1本のセッションに詰め込みすぎると後半で詰まります。
作業を複数セッションに分ける習慣が、実用上の対策になります。
これぐらいの規模の文章でも、一般的な資料を整理して文章を書くのには、Claude Sonnet 4.6 Mediumで十分でした。
というのも、Opusが差を出すのは医学・法律・科学論文のような、高度な専門推論だからです5。
一般向けの文章品質や構成、具体化にはその差は出てこないため、Opusを使うとむしろセッションのトークンを速く消費してしまいます。
なんとなくの体感ですが、Sonnet 4.6 Adaptive+Mediumで、Sonnet 4.5と同じぐらいの分量の作業ができます。
Opus だとすぐに制限がいっぱいになってしまうので、自分の使い方では、今のところ Sonnet 4.6 Adaptive+Mediumがよさそうです。
しばらくは、作業の一区切りごとに、セッション制限の割合を確認しておくとよさそうです。
2. トークン消費・応答時間を節約するには?
アダプティブ思考をオンにすると、推論トークンが乗ってきます。
推論トークンは出力トークンとは別に消費され、表示される回答の10〜30倍になることもあります6。
複雑なタスクで毎ターン推論が走ると、消費量の増え方がさらに急になります。
トークンを節約したいなら、作業フェーズによって設定を切り替えることも有効です。
たとえば調査・構成フェーズは、アダプティブ思考オン・Mediumで進め、編集・整形フェーズは、アダプティブをオフにします。
複数の資料をもとに構成を組んだりする作業は推論が役立ち、消費トークンに見合う効果がありますが、語調の修正、注釈の追加、表現の言い換えといった作業には推論チェーンは不要で、品質も変わりません。
あと、アダプティブ思考がオンだと、通常の応答よりもかなり時間がかかります。
つまり、「単純な編集だな」と思えば、アダプティブ思考をオフにすると、消費トークンを節約できます。
2.1. 入力トークンの累積構造
ここで重要なのは、Claudeの1回のやり取りで消費されるトークンは、「会話履歴全体」だということです。
今のメッセージだけではありません。
n ターン目の入力 = システムプロンプト + 会話履歴(1〜n-1ターン分)+ 今のメッセージこれは、Messages APIはステートレス設計で、常に会話の全履歴をAPIに送信するからです7
。
つまり、ユーザーには1行の短い質問に見えても、Claudeは毎回会話の全履歴を含む入力として受け取っています。
そのため、会話が進むほど毎ターンの入力が線形に増え、10ターン目の入力は1ターン目の約10倍の重さを持ちます。
O(n²)の蓄積で、後半になるほど1ターンあたりの消費が増える非線形な特性があるのです。
Anthropicのキャッシュ機能であるprompt cachingは確かに存在しますが、効くのはシステムプロンプトなど変化しない部分だけです。
会話履歴は毎ターン更新されるのでキャッシュが効かず、蓄積はそのまま続きます8。
2.2. セッション設計の方が効く
そのため、アダプティブ思考のオフだけでなく、「セッション設計」が重要です。
作業中に「この段落をもっと具体的に」「この表現を変えて」という反復的なやり取りが積み重なると、後半になるほど会話履歴の重さで消費が2乗に増えます。
そこで、大きな書き直しが発生しそうな場合は、現行の作業内容をファイルに保存して、新しい会話(⌘N)で渡し直す方が節約できます。
ファイルが状態の外部化として機能し、履歴の蓄積をリセットできます。
作業の区切りで成果物をファイルに書き出すと、トークン消費を抑えることが多いです。
3. まとめ
アダプティブ思考は推論機構の元栓で、工数はその深さのつまみです。
元栓が閉まっていれば工数は効きません。
Sonnet 4.5には推論機構がなかったため、4.6への移行でトークン消費の構造が変わっています。
推論を使う用途なら、アダプティブ思考オン・Mediumをベースにするのが妥当です。
編集・整形フェーズではアダプティブをオフにすることで、品質を落とさず消費を抑えられます。
セッション内の会話履歴の蓄積が最も支配的な要因なので、成果物の外部化も習慣にしておくといいでしょう。
High設定やOpusが必要かどうかは、実際のセッション消費を見ながら判断します。
以前、Opusでレート制限が頻発した経験があっても、4.8では構造が変わっているので改めて試す価値はあります9。
- 「At the default effort level (high), Claude almost always thinks. At lower effort levels, Claude may skip thinking for simpler problems.」 – Adaptive thinking – Claude API Docs
- 応答の丁寧さには多少影響しますが、推論トークンの消費という点では桁が変わらないようです。
- effortは「ふるまいへの示唆」であり、ハードな上限ではない。Low設定でも問題が十分に複雑であればClaudeは自律的に推論する。 – Interpreting Claude Adaptive Thinking Mode: 4 Major Upgrades
- Anthropicの公式ドキュメントでは、effortパラメータは「Combine effort with adaptive thinking for the best experience」とあり、推論チェーンの起動にはアダプティブ思考の有効化が前提とされている。アダプティブ思考をオフにすると推論が完全に停止し、effortはその深さではなく応答の丁寧さへの示唆としてのみ機能する。「If you want the model to stop thinking, you turn thinking off entirely」という記述もこの構造を裏付けている。 – Effort – Claude API Docs / Effort, Thinking, and How Claude Opus 4.7 Changed the Rules
- GPQA Diamond(PhD水準の科学的推論テスト)でのスコア比較:Claude Sonnet 4.6が74.1%、Claude Opus 4.6が91.3%。コーディングベンチマーク(SWE-bench)ではSonnet 4.6が79.6%、Opus 4.6が80.8%と差はわずか1.2ポイント。 – Claude Sonnet 4.6 vs Opus 4.6 – Which Model Should You Use
- 「Reasoning tokens can amount to 10 to 30 times more than the visible output.」 – Why You Hit Claude Limits So Fast: AI Token Limits Explained
- AnthropicのMessages APIはステートレス設計で、会話の文脈を保持する仕組みをサーバー側に持たない。そのためclaude.aiのUIを含むすべてのクライアントが、毎ターン会話履歴の全体をリクエストに含めて送信している。 – Using the Messages API – Claude API Docs
- prompt cachingはプレフィックスの一致によってキャッシュを再利用する仕組みで、毎ターン更新される会話履歴はキャッシュ対象外になる。システムプロンプトとツール定義など固定部分のみがキャッシュの恩恵を受ける。 – Prompt caching – Claude API Docs
- Opus 4.8の主な改善点:長期コーディングでのコンテキスト管理向上(コンパクション数の削減・回復精度向上)と、各effortレベルでの推論動作の信頼性向上。 – What’s new in Claude Opus 4.8 – Claude API Docs